Gestion des données industrielles : Comment le Unified Namespace met fin aux silos de données ?


Le défi de la gestion des données industrielles dans l’industrie manufacturière moderne
Les entreprises industrielles n’ont jamais produit autant de données. Machines, capteurs, ERP, MES, SCADA et plateformes IoT génèrent en continu des volumes importants d’informations, à un rythme toujours plus élevé.
Pourtant, malgré cette abondance, la majorité des industriels peinent encore à exploiter pleinement leurs données. Les informations restent dispersées dans des systèmes hétérogènes, cloisonnées entre les départements, les environnements IT et OT, et parfois même entre les sites de production. C’est là que TT PSC intervient : nous aidons les industriels à mieux exploiter leurs données pour soutenir la performance et l’efficacité opérationnelle.
Les usines modernes sont devenues des environnements complexes où plusieurs couches technologiques coexistent :
- les ERP pour la gestion des ressources et de la planification,
- les MES pour l’exécution et le pilotage de la production,
- les SCADA pour la supervision des automatismes,
- les capteurs et systèmes IoT pour la remontée de données temps réel sur l’état des équipements, l’énergie ou la sécurité.
Chaque couche apporte de la valeur. Le problème n’est pas la donnée elle-même, mais son manque de cohérence, de contexte et de continuité. Or, une gestion efficace des données industrielles est aujourd’hui un levier essentiel pour améliorer la performance opérationnelle, renforcer la résilience des sites et atteindre des objectifs de durabilité.
Une conséquence directe : perte de visibilité et inefficacité opérationnelle
Lorsque les données restent fragmentées, les impacts sont immédiats :
- Manque de visibilité globale
Les équipes de direction ne disposent pas d’une vision consolidée et contextualisée des opérations industrielles. - Dépendance aux traitements manuels
Les opérateurs et les ingénieurs passent un temps excessif à consolider des données brutes, souvent via des extractions et des fichiers intermédiaires, au détriment de l’analyse. - Décisions tardives
Les informations arrivent trop lentement pour permettre des ajustements rapides, qu’il s’agisse d’optimisation de la production ou de maintenance prédictive.
Selon McKinsey, une mauvaise gestion des données dans l’industrie peut entraîner une baisse de productivité comprise entre 20 et 30%.
Gartner estime par ailleurs que, d’ici 2026, 70% des entreprises des secteurs à forte intensité d’actifs augmenteront fortement leurs investissements dans les solutions de gestion des données industrielles et d’intégration des systèmes pour répondre à ces enjeux.
Le coût réel des silos de données industrielles
Les silos de données ne constituent pas uniquement un problème technique. Ils ont un impact direct sur la performance économique et la compétitivité des entreprises industrielles.
- Opportunités non exploitées : Sans données unifiées, il devient difficile d’optimiser les processus de production ou de maximiser l’utilisation des équipements.
- Hausse des coûts IT et OT : IDC estime qu’un reporting inefficace et une gestion fragmentée des données peuvent augmenter les coûts IT/OT de 15 à 20% par an.
- Décisions ralenties : Les managers ne disposent pas d’indicateurs fiables et en temps réel pour piloter efficacement leurs activités.
- Freins à l’innovation : L’intelligence artificielle, l’analytique avancée et les jumeaux numériques reposent sur des données cohérentes, contextualisées et accessibles. Sans cela, ces initiatives restent limitées.
Pour dépasser ces contraintes, il ne suffit plus d’ajouter des outils. Il faut repenser la manière dont les données industrielles sont structurées, partagées et exploitées.
Les limites des approches traditionnelles à l’ère de l’Industrie 4.0
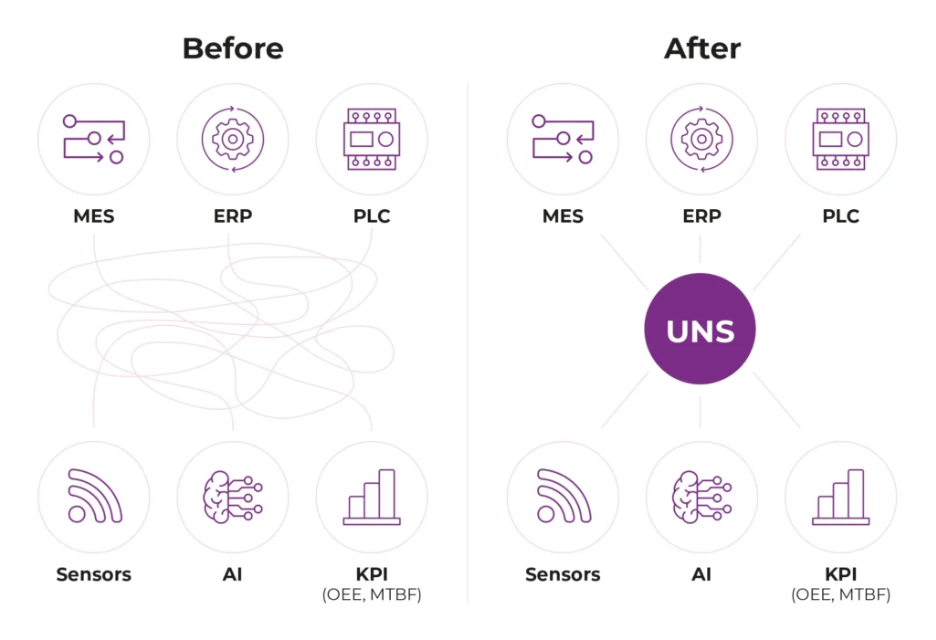
Historiquement, l’intégration des systèmes industriels s’est faite par des connexions point à point :
ERP vers MES, MES vers SCADA, puis vers d’autres applications spécialisées.
Cette approche a permis de répondre à des besoins ponctuels, mais elle a surtout conduit à une architecture complexe, rigide et coûteuse à maintenir.
Ses limites sont aujourd’hui bien identifiées :
- chaque nouvelle machine ou application nécessite des développements spécifiques,
- les formats de données restent hétérogènes et peu exploitables,
- la montée en charge est difficile, notamment lors de l’ajout de nouvelles lignes ou de nouveaux sites,
- l’accès aux données reste fragmenté, obligeant les équipes à multiplier les outils et les interfaces.
Cette situation complique également l’optimisation des processus industriels. Même les solutions de pilotage de la performance, comme les outils OEE, peinent à fournir des analyses fiables sans données cohérentes et disponibles en temps réel. Résultat : la transformation digitale ralentit, les coûts augmentent, et le potentiel de l’automatisation avancée et de l’IA reste largement sous-exploité.
Comparaison des approches d’intégration des données industrielles
| Approche | Description générale | Avantages | Limites |
|---|---|---|---|
| Intégration point-à-point | Chaque système est directement connecté aux autres (ex. PLC → SCADA → MES → ERP) via des liens personnalisés et directs. | – Simple dans les environnements de petite taille – Fiable dans les architectures traditionnelles ISA-95 | – Coûts d’intégration élevés – Faible évolutivité – Données fragmentées et reporting retardé |
| Enterprise Service Bus (ESB) | Un “bus” central de données assure la communication entre les systèmes (MES, ERP, SCADA) et standardise les formats de messages. | – Découple les systèmes (pas de dépendances point-à-point) – Supporte la messagerie en temps réel | – Nécessite des modèles de données cohérents – Pas de contexte unifié – Support limité pour les flux de capteurs à haute fréquence |
| Data Lake | Un large référentiel qui stocke les données brutes de l’ensemble de l’entreprise, principalement pour l’analytique et le reporting historique. | – Toutes les données au même endroit – Adapté à l’analytique et au machine learning – Peut stocker des données de n’importe quel format | – Non temps réel – Pas de contexte ou d’unification – Inadapté au contrôle en temps réel de la production |
| Unified Namespace (UNS) | Une couche centralisée et contextualisée, basée sur un modèle publish/subscribe (ex. MQTT), qui agrège toutes les données en direct dans un espace commun et structuré. | – Données en temps réel avec contexte complet – Langage de données partagé – Scalable et coûts d’intégration réduits sur le long terme | – Nécessite la conception et la gouvernance du namespace – Changement culturel et organisationnel IT/OT – Effort initial plus élevé et courbe d’apprentissage |
Du cloisonnement des données au Unified Namespace
Face à ces constats, une question revient systématiquement chez les industriels :
comment structurer les données industrielles pour en faire un véritable levier de performance ?
Le Unified Namespace (UNS) apporte une réponse structurante à ce problème. Il consiste à rassembler les données issues des machines, des systèmes et des applications dans une couche unique, organisée et contextualisée, avec une structure commune compréhensible par l’ensemble de l’écosystème industriel.
L’usine devient ainsi le point central des flux de données, des opérations et des initiatives de transformation digitale. Sur le plan technique, le Unified Namespace permet de diffuser les données en continu depuis les équipements, les systèmes OT et les applications IT vers une couche unique qui standardise les formats, ajoute du contexte et supprime les intégrations point à point rigides. Il agit comme un socle d’interopérabilité temps réel entre IT et OT.
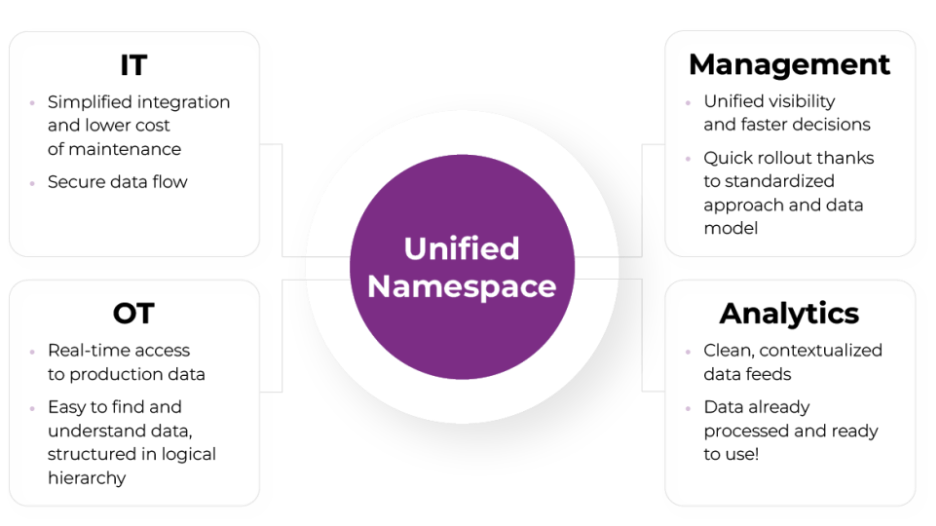
Les bénéfices concrets du Unified Namespace
La mise en place d’un Unified Namespace apporte des bénéfices mesurables :
- une intégration plus simple et plus cohérente des systèmes industriels,
- un accès en temps réel aux données opérationnelles pour l’ensemble des parties prenantes,
- une meilleure gouvernance des données, réduisant les erreurs et les risques de non-conformité,
- une base solide pour la maintenance prédictive, le machine learning et les initiatives de durabilité.
Une approche moderne et évolutive de la donnée industrielle
Les architectures de données industrielles modernes reposent sur un principe clé : disposer d’une source unique de vérité, fiable et partagée. Le Unified Namespace s’inscrit naturellement dans cette logique en éliminant les incohérences, en standardisant les structures de données et en garantissant que toutes les équipes travaillent sur les mêmes informations.
Trois piliers structurent cette approche :
- Collecter et enrichir les données à grande échelle, en temps réel et avec le contexte nécessaire.
- Analyser les données dans leur contexte opérationnel, pour faciliter la détection d’anomalies et la prise de décision.
- Partager les données de manière maîtrisée, sans multiplier les intégrations ni les duplications.
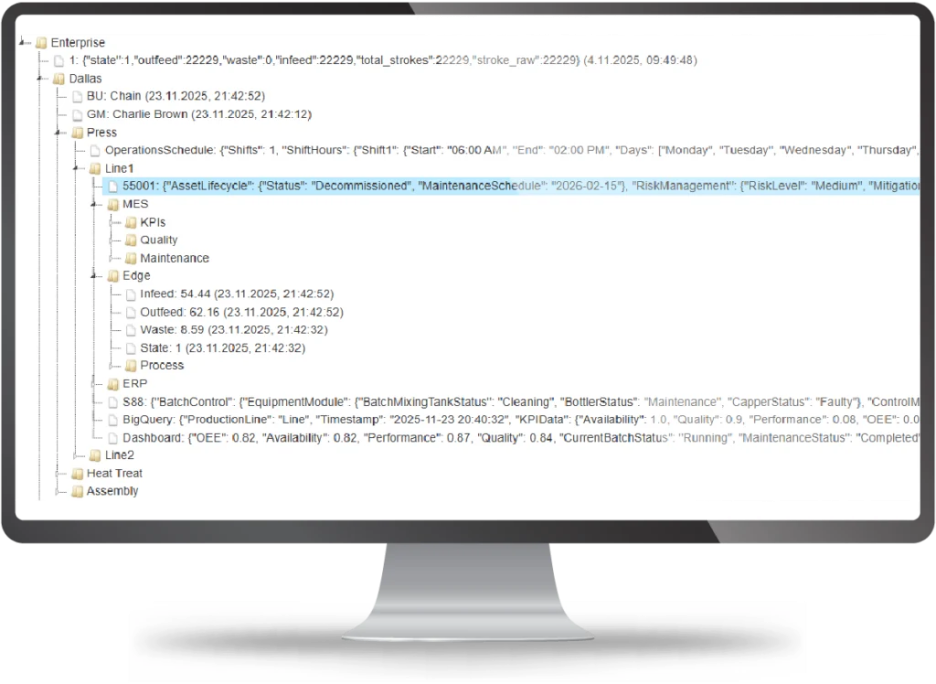
Autre avantage clé : la capacité à évoluer de l’edge au cloud. Le Unified Namespace permet de déployer une architecture cohérente, depuis une ligne de production jusqu’à des environnements multi-sites. Il rapproche également les données d’ingénierie et les données opérationnelles, facilitant la collaboration sur l’ensemble du cycle de vie des actifs industriels.
Mettre en œuvre un Unified Namespace : les prérequis essentiels
Pour adopter un Unified Namespace dans de bonnes conditions, les industriels doivent :
- disposer d’une connectivité fiable avec les machines et les systèmes existants,
- définir un modèle de données clair et partagé (noms, hiérarchie, structure),
- identifier les sources de données prioritaires à intégrer en premier.
La mise en œuvre repose généralement sur la configuration des points de collecte, le déploiement d’un broker MQTT ou d’une infrastructure compatible Sparkplug B, puis l’organisation des flux dans une structure unifiée. Une fois les fondations en place, l’architecture peut être étendue progressivement, sans remise en cause globale.
Études de cas réelles sur le Unified Namespace (UNS)
1. UNS pour une gestion optimisée des recettes dans l’agroalimentaire
Un des plus grands producteurs mondiaux de produits alimentaires et de boissons a collaboré avec TT PSC pour moderniser la gestion des recettes dans ses sites européens. En intégrant une plateforme IoT avec un Unified Namespace, l’entreprise a unifié les flux de données entre MES, ERP et systèmes d’automatisation, amélioré la traçabilité et réduit le gaspillage lié aux recettes obsolètes. Cette approche a permis d’éliminer les erreurs coûteuses – un risque majeur dans le secteur, illustré par des rappels de produits très médiatisés. Découvrez l’étude complète : Gestion de recettes plus intelligente grâce au UNS dans l’agroalimentaire
2. Contrôle distribué sur une ligne SMT avec UNS
Sur une ligne d’assemblage SMT, une architecture de contrôle distribuée hétérachique a été déployée avec le support du UNS. En connectant des stations comme OMS, IOI et MRS via un modèle publish/subscribe, l’équipe a amélioré la surveillance, l’utilisation des ressources et la détection des erreurs. Les simulations ont montré un OEE supérieur et une flexibilité accrue par rapport aux lignes traditionnelles Industrie 3.0.
(Source : revista Observatorio de la Economía Latinoamericana, 2024)
3. Échange de données unifié pour le secteur maritime
Dans le secteur maritime, les données étaient dispersées entre ports, navires et prestataires. L’implémentation d’un Unified Namespace comme couche de données partagée a permis un échange en temps réel d’informations standardisées. Cela a renforcé la collaboration, la conformité et la prise de décision, donnant à l’écosystème un avantage compétitif et démontrant la valeur du UNS au-delà des environnements manufacturiers.
Le Unified Namespace, socle de l’Industrie 4.0
Atteindre l’excellence opérationnelle ne consiste plus uniquement à collecter des données, mais à les exploiter en temps réel, de manière cohérente, à l’échelle des machines, des systèmes et des équipes.
Le Unified Namespace aligne les mondes IT et OT autour d’une couche de données commune, apportant visibilité, réactivité et capacité d’évolution.
Dans un contexte industriel de plus en plus complexe, il s’impose comme un socle durable pour les écosystèmes digitaux industriels, en particulier lorsqu’il est associé à des outils de pilotage de la performance, de suivi de production ou de gestion énergétique.