Flaky Tests in CI/CD: Root Causes, Hidden Costs and Systematic Ways to Restore Test Reliability


Automated testing is now a standard part of how we build modern software. Most teams depend on unit tests and API tests and UI automation to check functionality and reduce the risk of bugs reaching end users. When this automation works well, it builds confidence and allows teams to release their work faster. However, many teams find that automation brings its own set of unique challenges. One of the most common and annoying problems is the presence of flaky tests, where tests fail unpredictably and fail randomly across different test runs.
These tests do not fail in a consistent way and their behaviour often confuses developers and testers alike. Over time flaky tests can actually cause more harm than having no tests at all. They lead to unreliable automated test results, false alarms, and confusion during the development process. These issues often reflect rushed writing automation tests, weak test design, unstable environments, or overlooked external factors. This article explains how flaky tests occur, how to detect flaky tests, and how teams can fix flaky tests and prevent them long term.
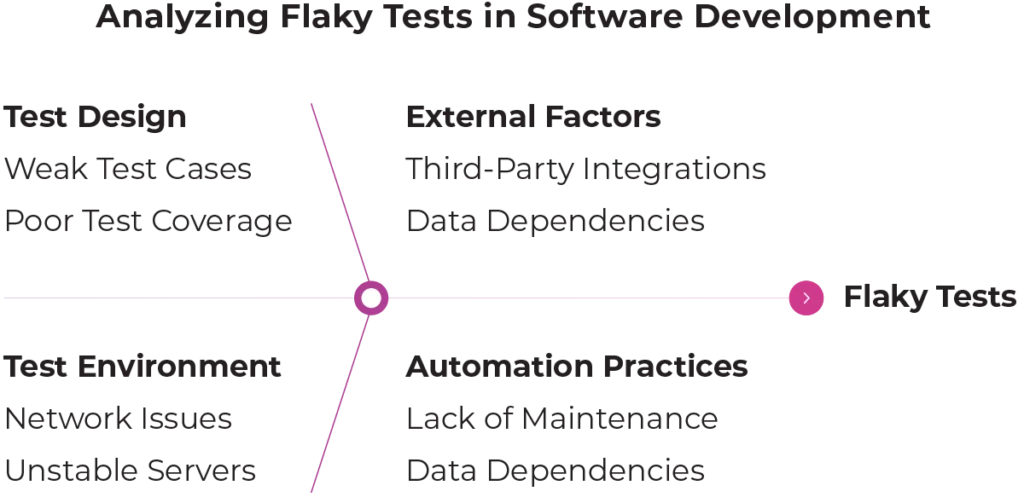
What Are Flaky Tests?
A flaky test is an automated test that gives inconsistent test results. The same test might pass once and fail the next time even though there were no code changes . Some common examples include a test that passes on a local computer but fails in the pipeline. Another case is a test that fails once and then passes immediately when it is run again. We might also see failures only during busy hours or when the system is under a heavy load. It is important to tell the difference between flaky tests and valid failures. A valid failure usually means there is a real bug in the software. A flaky failure usually shows a weakness in the test itself or the environment where it runs.
Why Flaky Tests Are a Serious Problem?
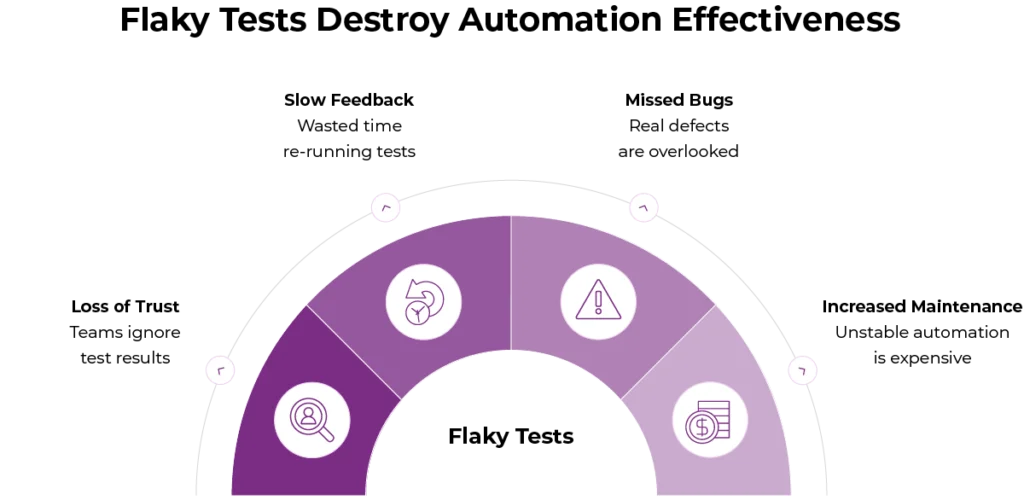
Teams might think flaky tests are just a minor inconvenience at first. In reality, they can slowly destroy the effectiveness of the automation. One major issue is the loss of trust. When test failures happen at random, teams stop trusting the results. Developers might start ignoring failures because they assume they are false alarms and this causes automation to lose its value. Flaky tests also slow down feedback cycles. Time is wasted re-running pipelines and checking logs and manually confirming if a failure is real. This directly hurts delivery speed and team morale.
There is also a high risk of missing real bugs. When flakiness becomes normal genuine defects can be overlooked. A real failure might be dismissed as just another flaky test and this allows bugs to escape into production. These tests also increases maintenance effort. Maintaining unstable automation becomes more expensive over time than building it correctly in the first place.
Common Areas Where Flaky Tests Appear in Automated and End-to-End Testing
Flaky behaviour can happen at any level of software testing although some areas are more vulnerable. Unit test flakiness is often caused by shared state or order dependency or relying on system time. API tests might fail intermittently because of unstable data or network latency or dependencies on external factors. UI and end to end tests are the most common source of flakiness. They interact with browsers and asynchronous content and dynamic elements which all increase uncertainty. While UI tests get the most attention it is important to remember that poor design can make any test flaky.
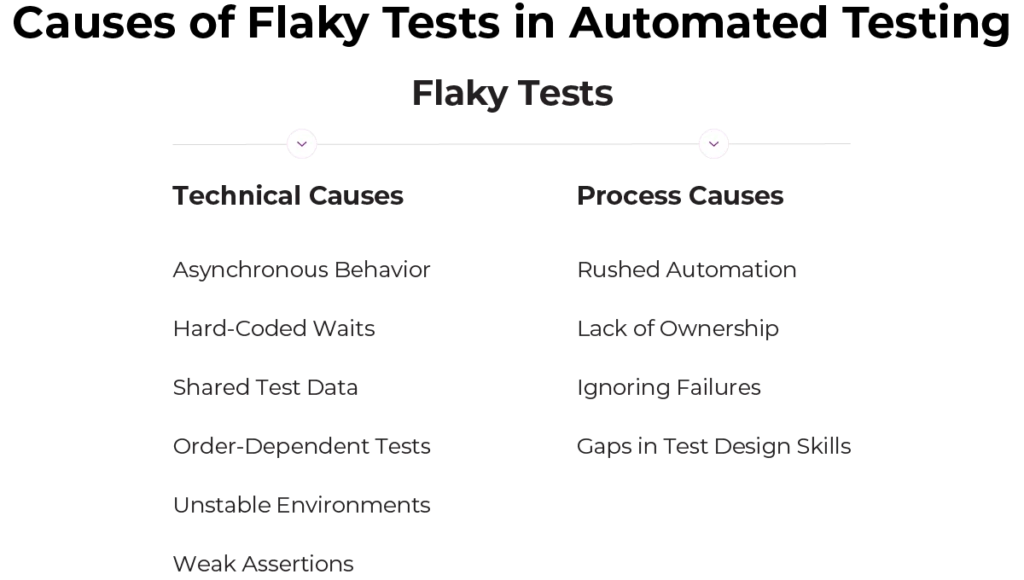
Understanding the Common Causes and Identifying Flaky Tests Early
- Asynchronous behavior and timing issues
Modern applications rarely respond instantly. Data is loaded asynchronously, background jobs run at different speeds, and UI elements often appear with delays. When a test assumes everything happens immediately, it may pass on fast runs and fail on slower ones. A typical example is clicking a button and instantly asserting that a message is visible.
- Hard-coded waits
Hard-coded waits are a common quick fix, but they make tests fragile. If the wait is too short, tests fail intermittently. If it is too long, the entire test suite becomes slow and inefficient. In both cases, the test relies on assumptions that do not hold across all environments.
- Shared test data
Tests that depend on shared users, records, or database states often interfere with each other. Multiple tests updating the same account or assuming specific records exist can lead to unpredictable results, especially when tests run in parallel or in a different order.
- Order-dependent tests
Some tests only pass when executed after specific others. This usually happens when setup or cleanup steps are incomplete. Global variables, static configurations, or leftover data cause failures to appear randomly when the execution order changes in CI.
- Unstable environments and external dependencies
Test environments are often less stable than production due to limited resources or misconfigured services. External dependencies such as payment providers, email systems, or third-party APIs are outside the team’s control. Network issues, rate limits, or temporary outages can trigger failures unrelated to code quality.
- Weak or overly detailed assertions
Assertions that rely on dynamic text, exact timestamps, or precise UI layouts tend to break easily. Reliable tests focus on meaningful outcomes rather than implementation details.
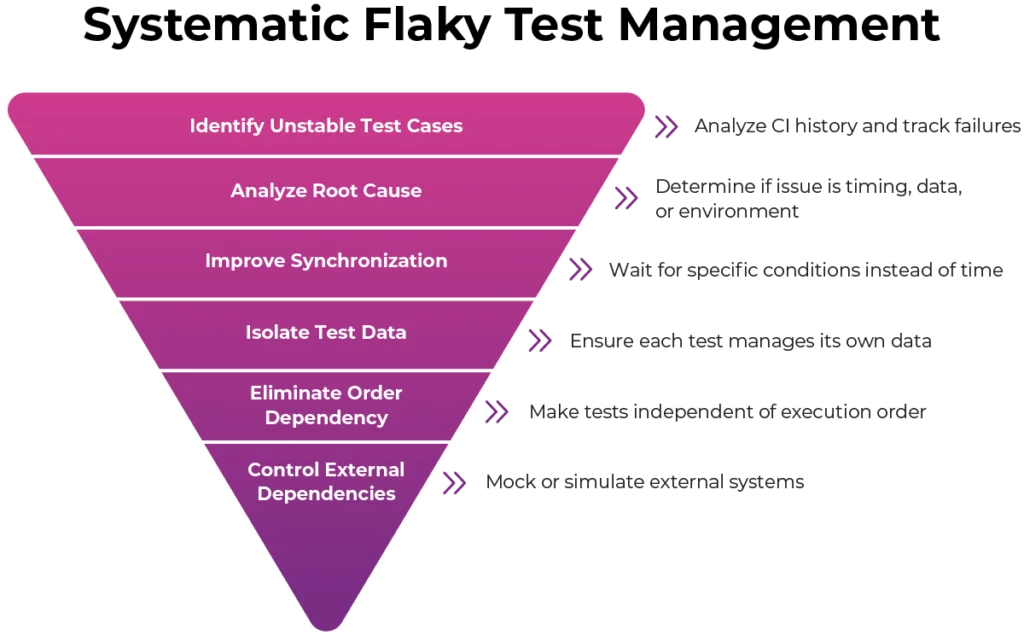
Flaky Test Management: A Systematic Approach to Stabilizing Automated Tests
We should not fix flaky tests at random because a structured approach is much more effective.
- Identifying unstable tests cases – Teams can analyse CI history and track failures and use automatic re-runs to find patterns. Maintaining visibility helps us prioritize the most problematic tests.
- Analyse the root cause for each test – We should check if the issue is related to timing or data or environment or external dependencies. This analysis prevents us from using temporary fixes that only hide the real problem.
- Improve synchronization – Instead of waiting for time to pass tests should wait for specific conditions to be met. Waiting for elements to be visible or for network calls to finish aligns the test with how the application actually works.
- Focus on isolating test data – Each test should manage its own data by creating unique records to reduce interference. Disposable data strategies can be very effective when cleanup is difficult.
- Eliminate order dependency – Tests should be independent and able to run in any order. We should reset the state before execution and avoid global data and use proper setup and teardown logic.
- Controlling external dependencies – External systems should be mocked or simulated to reduce unpredictability and improve reliability.
- Strengthen assertions – Assertions should focus on outcomes that matter to users and the business. We should avoid checks that depend on layout details or exact text or timing assumptions.
- Quarantine to fix tests over time – If flaky tests block progress, we may need to isolate them temporarily while they are scheduled for a proper fix. Reducing flakiness is usually an incremental process rather than a one time effort.
Preventing Flaky Tests
Prevention is always easier than recovery. We should design tests carefully from the start because shortcuts taken early lead to long term issues. It is also important to review test code seriously. Test code deserves the same review standards as production code to catch fragile patterns early. Teams should invest in test infrastructure like strong frameworks and utilities to reduce the likelihood of flakiness. Finally, we should measure stability. Tracking pass rates and failure patterns and the time spent on fixes provides valuable insight because improvement is difficult without measurement.
Understanding the Causes of Flaky Tests and Building Reliable CI/CD Automation
Flaky tests are one of the most damaging problems in test automation. Although they appear random, they usually have clear and identifiable causes. By understanding why they occur and addressing them systematically teams can restore confidence in automation. Reliable tests provide faster feedback and reduce frustration and improve overall software quality. Flaky tests are not inevitable and they can be reduced significantly or even eliminated with careful design and the right mindset.