Jak zadbać o bezpieczeństwo aplikacji serverless w AWS?


Konferencja AWS re:Invent 2019, podobnie jak jej poprzednie edycje, obfitowała w ciekawe wykłady typu breakout sessions, których celem było przybliżenie uczestnikom wybranego zagadnienia technicznego związanego z chmurą Amazon Web Services. Jedno z takich wystąpień zainspirowało mnie do napisania kilku słów na temat bezpieczeństwa aplikacji stworzonych w modelu serverless. Zaufanie świata biznesu do tej architektury systematycznie rośnie, nie tylko wśród startupów i małych firm, ale także w dużych organizacjach. Wiele wskazuje na to, że w najbliższych latach trend ten się utrzyma i liczba produkcyjnych wdrożeń serverless będzie coraz większa. Dlatego zdecydowanie warto przyjrzeć się narzędziom, które AWS udostępnia, aby pomóc programistom, administratorom i architektom minimalizować ryzyko wycieku danych czy przejęcia kontroli nad ich oprogramowaniem.
Decydując się na wdrożenie aplikacji w modelu serverless, dzielimy odpowiedzialność za jej bezpieczeństwo z dostawcą usług chmurowych. Opisuje to tzw. model współdzielonej odpowiedzialności (ang. Shared Responsibility Model) [1]. Amazon Web Services musi zadbać o zabezpieczenie całej infrastruktury obliczeniowej i sieciowej, właściwą konfigurację systemów operacyjnych i części oprogramowania (hypervisora, firewalla, itp.), instalowanie aktualizacji i poprawek bezpieczeństwa na bieżąco, czy szyfrowanie danych i ruchu sieciowego. W gestii klienta, będącego bezpośrednim użytkownikiem usług AWS, leży natomiast implementacja swojego programu w taki sposób, aby uniemożliwić potencjalnym atakującym dostęp do poufnych zasobów czy wykonanie niepożądanych działań. Innymi słowy – klient sam odpowiada za błędy w kodzie i logice biznesowej aplikacji, a także za właściwe monitorowanie istotnych parametrów i logowanie zdarzeń.
Uwierzytelnianie użytkowników
Obecnie, niemal każda aplikacja biznesowa posiada mechanizm kontroli dostępu. Chcemy mieć pewność, że użytkownik jest rzeczywiście tym, za kogo się podaje oraz ma dostęp tylko do tych zasobów, do których mieć powinien. Najczęściej stosowaną metodą uwierzytelniania jest wykorzystanie hasła statycznego, które zwykle jest zapisane w bazie danych. Oczywiście przechowywanie haseł jako zwykły, niezaszyfrowany tekst (ang. plaintext) jest praktyką absolutnie niedopuszczalną.
Niewiele lepszym rozwiązaniem jest ich hashowanie kiepskimi funkcjami skrótu kryptograficznego, jak np. MD5 czy SHA1, które od dawna przestały być uważane za bezpieczne. Jeśli ktoś podchodzi do kwestii bezpieczeństwa poważnie, powinien skoncentrować swoją uwagę na jednym z nowoczesnych algorytmów hashujących, przykładowo Bcrypt czy PBKDF2. Posiadają one wbudowane mechanizmy key stretchingu oraz dodawania soli, dzięki czemu są w wysokim stopniu odporne na ataki siłowe (ang. brute force), słownikowe czy te z wykorzystaniem tablic tęczowych (ang. rainbow tables).
Istnieje również możliwość uwierzytelniania użytkowników bez konieczności przechowywania haseł w jakiejkolwiek bazie danych, ani nawet przesyłania ich między klientem a serwerem, a to wszystko dzięki wykorzystaniu protokołu SRP (ang. Secure Remote Password). W dużym uproszczeniu: zamiast hasła, wymaga on przechowywania weryfikatora, czyli wartości obliczonej według wzoru v = gx mod N, gdzie g jest tzw. generatorem grupy, N – odpowiednio dużą liczbą pierwszą, a x – wartością obliczoną na podstawie nazwy użytkownika, hasła oraz soli poprzez zastosowanie jednokierunkowej funkcji skrótu.
Zadaniem stojącym przed potencjalnym atakującym, który zechce złamać protokół, jest obliczenie x, czyli znalezienie logarytmu dyskretnego. Nawet znając wartości N oraz g, jest to problem niezwykle trudny obliczeniowo (przy założeniu, że liczba N spełnia określone kryteria). Protokół SRP może zatem stanowić ciekawą, ale i wymagającą w implementacji alternatywę dla popularnego przechowywania hashy haseł w bazie danych.
Czy w takim wypadku musimy zatrudniać programistę ze znajomością arytmetyki modularnej, aby móc cieszyć się bezpiecznym procesem uwierzytelniania w naszej aplikacji? W świecie serverless – nie. Takich programistów zatrudnił już Amazon, żeby wykonali za nas całą żmudną pracę. Dlatego możemy (a nawet powinniśmy) skorzystać z usługi Amazon Cognito, która uwolni nas od odpowiedzialności za bezpieczne przechowywanie danych dostępowych użytkowników.
Dzięki bibliotekom do wielu popularnych języków programowania ułatwi również implementację logiki uwierzytelniania, zarówno z wykorzystaniem protokołu SRP, jak i bez niego. Cognito umożliwia stworzenie własnej puli użytkowników oraz integrację z zewnętrznymi dostawcami tożsamości, takimi jak Google, Facebook, Amazon, czy dowolnymi innymi, którzy wspierają protokół OpenID Connect lub SAML. Ułatwia to wdrożenie jednej z dobrej praktyk bezpieczeństwa, czyli centralizacji zarządzania tożsamością, co przekłada się na ograniczenie liczby możliwych wektorów ataku.
Z punktu widzenia aplikacji istnieje wtedy tylko jeden magazyn tożsamości, chociaż w rzeczywistości dane użytkowników mogą być przechowywane w wielu różnych miejscach. Wykorzystanie Amazon Cognito w naszej serverlessowej układance to zdecydowanie krok w dobrym kierunku, jeśli zależy nam na wysokim poziomie bezpieczeństwa.
Kontrola dostępu do REST API
Jest wysoce prawdopodobne, że Twoja aplikacja serverless wykorzystuje (lub będzie wykorzystywała) REST API do wymiany danych pomiędzy różnymi komponentami.
W chmurze AWS do tworzenia i zarządzania endpointami API istnieje dedykowana usługa o nazwie Amazon API Gateway. Pomimo faktu, że w tym przypadku również dzielimy odpowiedzialność za bezpieczeństwo z dostawcą, należy pamiętać, że to do nas należy obowiązek zadbania o właściwą konfigurację. Jednym z kluczowych jej elementów jest tzw. authorizer, czyli mechanizm wbudowany w API Gateway, którego zadaniem jest kontrola dostępu do naszego API. Rozważmy fragment architektury prostej aplikacji, przedstawiony na poniższym diagramie.
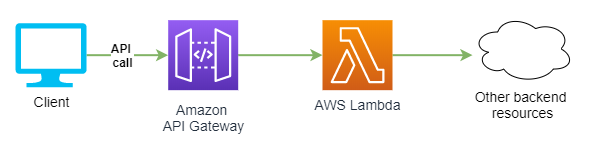
Aplikacja kliencka wysyła żądania do jednego lub wielu endpointów REST API udostępnianych za pośrednictwem usługi Amazon API Gateway, która następnie wywołuje odpowiednie funkcje Lambda. Jeśli aplikacja posiada mechanizm uwierzytelniania, prawdopodobnie chcielibyśmy, aby tylko zalogowani użytkownicy mogli wysyłać żądania do API i tym samym uzyskać dostęp do chronionych zasobów. Wykorzystując opisywaną wcześniej usługę Amazon Cognito – sprawa jest prosta.
Jednak aby lepiej zrozumieć mechanizm ograniczenia dostępu do API wykorzystujący integrację z Cognito, zacznijmy od szybkiego wyjaśnienia czym jest JWT (ang. JSON Web Token) [2]. Jest to standard opisujący bezpieczny sposób wymiany informacji w formie obiektu JSON, który zostaje zakodowany i podpisany kryptograficznie, dzięki czemu możemy być (niemal) pewni, że dane rzeczywiście pochodzą z oczekiwanego przez nas źródła.
Typowy token JWT składa się z trzech części – nagłówka, danych właściwych (tzw. payload) oraz podpisu (sygnatury) – rozdzielonych kropką. Usługa Amazon Cognito, w przypadku poprawnego uwierzytelnienia użytkownika, zwraca do naszej aplikacji aż trzy tokeny JWT:
- ID token
- Access token
- Refresh token
Dwa pierwsze z nich zawierają poświadczenia dotyczące tożsamości użytkownika i są ważne przez godzinę od momentu wygenerowania. Refresh token umożliwia ponowne wygenerowanie ID oraz Access tokenu po upływie terminu ich ważności, bez konieczności ponownego uwierzytelniania użytkownika. Dla każdej puli Cognito generowane są dwie pary kluczy kryptograficznych RSA. Jeden z kluczy prywatnych jest wykorzystywany do utworzenia cyfrowej sygnatury tokenu.
Znając klucz publiczny, zarówno nasza aplikacja kliencka, jak i API Gateway mogą łatwo zweryfikować, czy użytkownik posługujący się danym JWT rzeczywiście pochodzi z naszej puli, a także czy nie próbuje podszywać się pod innego użytkownika. Każda próba ingerencji w ciąg znaków tworzący token sprawi, że sygnatura stanie się nieważna.
Posiadając taką wiedzę, powoli zbliżamy się do wyjaśnienia sekretu działania authorizera zintegrowanego z pulą Cognito. Spójrzmy na zmodyfikowaną wersję przedstawionego wcześniej diagramu architektury.
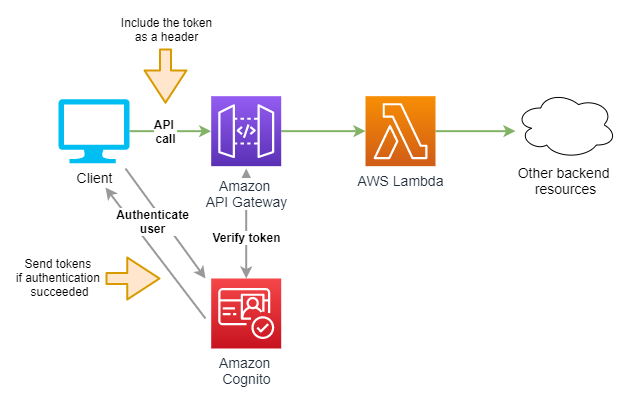
Żądanie do REST API, wysyłane przez aplikację kliencką, tym razem zawiera dodatkowy nagłówek HTTP o nazwie Authorization. Jako wartość tego nagłówka ustawiamy ID token lub Access token, przesłany wcześniej do aplikacji w odpowiedzi na pomyślne uwierzytelnienie użytkownika. Usługa API Gateway, zanim przekaże żądanie do funkcji Lambda, upewni się, czy token rzeczywiście został podpisany kluczem powiązanym z właściwą pulą Cognito oraz czy termin ważności tokenu nie upłynął. Jeśli weryfikacja zakończy się błędem, żądanie zostanie odrzucone.
Zatem nawet jeśli potencjalny atakujący odgadnie adres URL endpointu, nie będzie w stanie pomyślnie wysłać żadnego żądania do API nie będąc zarejestrowanym użytkownikiem naszej aplikacji. Rozwiązanie jest proste, eleganckie i bezpieczne, a przy okazji stanowi kolejny argument za tym, aby używać usługi Amazon Cognito.
Innym dostępnym typem authorizera jest Lambda authorizer, który przydaje się w sytuacjach, kiedy z jakiegoś powodu nie możemy użyć Cognito. Jak sama nazwa wskazuje, to rozwiązanie wykorzystuje funkcję Lambda uruchamianą w momencie nadejścia żądania do endpointu. Funkcja zawiera naszą własną logikę weryfikacji żądania na podstawie dostarczonego tokenu, bądź też na podstawie nagłówków i parametrów przesłanych razem z tym żądaniem. Jako wynik działania Lambdy musi zostać zwrócony obiekt zawierający politykę IAM, która określa czy API Gateway powinien zaakceptować, czy odrzucić żądanie.
Bezpieczne funkcje Lambda
Pisząc o bezpieczeństwie aplikacji serverless, nie sposób pominąć kwestii dotyczących funkcji Lambda. Jak już zostało wspomniane, dostawca usług chmurowych odpowiada za właściwą konfigurację środowiska uruchomieniowego i całej powiązanej z nim infrastruktury, a programista – za napisanie kodu wolnego od podatności i luk mogących stanowić wektor ataku. Jedną z takich podatności, wymienioną na pierwszym miejscu w zestawieniu OWASP Serverless Top 10 [3], jest tzw. wstrzyknięcie (ang. injection), które wielu osobom może się kojarzyć z popularnym i dobrze opisanym w rozmaitych źródłach atakiem SQL Injection.
Dla przypomnienia: polega on na niezamierzonym wykonaniu zapytania SQL (lub jego fragmentu) umieszczonego przez atakującego w danych wejściowych, które nasza aplikacji przetwarza bez uprzedniego filtrowania. W modelu serverless, tego typu dane niekoniecznie muszą pochodzić bezpośrednio z interfejsu użytkownika.
Funkcje Lambda często są uruchamiane w odpowiedzi na nadejście określonego zdarzenia z innej usługi AWS, jak np.: utworzenie nowego pliku
w wiadrze S3, modyfikacja rekordu w tabeli DynamoDB czy pojawienie się powiadomienia w topicu SNS. Obiekt event, który przechowuje zestaw informacji na temat takiego zdarzenia i jest dostępny w głównej metodzie Lambdy, w pewnych przypadkach również może zawierać kod „wstrzyknięty” przez atakującego.
Z tego powodu niezwykle istotne jest, aby każdy bajt danych wejściowych, który trafia do naszej funkcji z dowolnego źródła, został odpowiednio przefiltrowany, zanim zostanie użyty w zapytaniu SQL lub w poleceniu powłoki systemowej. Jakie niebezpieczeństwo grozi nam w tym drugim przypadku? Wszystkie popularne języki programowania posiadają funkcje lub biblioteki umożliwiające wykonywanie poleceń powłoki z poziomu kodu. Z technicznego punktu widzenia, nic nie stoi na przeszkodzie, aby robić to również w funkcjach Lambda, ale…
W celu lepszego zrozumienia możliwego wektora ataku, przypomnijmy pokrótce podstawy działania usługi Lambda.

Źródło: Security Overview of AWS Lambda [1]
Do uruchamiania naszych funkcji, AWS używa maszyn wirtualnych specjalnego typu, tzw. MicroVMs [4]. Każda instancja MicroVM może być wykorzystana ponownie dla potrzeb różnych funkcji w obrębie danego konta. Również każda taka instancja może zawierać wiele środowisk wykonawczych (są to pewnego rodzaju kontenery), w których działa wybrane przez użytkownika środowisko uruchomieniowe, np. Node.js, JVM czy Python. Środowiska wykonawcze nie są współdzielone pomiędzy różnymi funkcjami, jednak – co istotne – mogą być wykorzystane ponownie do uruchomienia kolejnych wywołań tej samej Lambdy.
Zatem jeśli w kodzie wywołujemy polecenie powłoki systemowej, które jest tworzone dynamicznie i zawiera nieprzefiltrowane dane wejściowe, atakujący może wykorzystać ten fakt do przejęcia kontroli nad środowiskiem wykonawczym, a tym samym nad innymi wywołaniami funkcji. Często pozwoli mu to na uzyskanie dostępu do poufnych informacji przechowywanych na przykład w bazie danych bądź w plikach umieszczonych w katalogu /tmp, a także zniszczenie niektórych zasobów aplikacji. Podatność ta została opisana pod nazwą RCE (ang. Remote Code Execution) [5].
Oprócz filtrowania i walidacji danych wejściowych, jedną z najważniejszych praktyk bezpieczeństwa dotyczących usługi AWS Lambda jest stosowanie zasady minimalnych uprawnień (ang. principle of least privilege). Aby ją poprawnie wdrożyć, musimy zadbać o spełnienie dwóch założeń:
- Każda Lambda w naszej aplikacji powinna posiadać przypisaną osobną rolę IAM. Niedopuszczalne jest tworzenie jednej, wspólnej roli dla wszystkich funkcji.
- Rola każdej Lambdy powinna zezwalać na tylko te operacje, które rzeczywiście są wykonywane. Należy unikać stosowania symbolu wieloznacznego (*, tzw. wildcard) w politykach.
Prosty przykład praktycznego zastosowania zasady: jeśli zadaniem danej funkcji jest odczyt rekordów z bazy danych DynamoDB, to przypisana rola IAM musi zezwalać tylko na wykonanie operacji odczytu z konkretnej, potrzebnej w tym przypadku tabeli. W pewnych sytuacjach możemy pójść o krok dalej i ograniczyć dostęp tylko do wybranych rekordów w tabeli oraz wybranych atrybutów tych rekordów [6]. Nawet jeśli atakujący będzie w stanie nas przechytrzyć i uzyska dostęp do środowiska wykonawczego Lambdy, stosowanie zasady minimalnych uprawnień pozwoli znacznie ograniczyć rozmiary wyrządzonych przez niego szkód.
Przechowywanie danych dostępowych
Łatwo zauważyć, że korzystając z bazy danych Amazon DynamoDB nie musimy martwić się o proces nawiązywania połączenia oraz uwierzytelniania za pomocą nazwy użytkownika i hasła, co zwykle ma miejsce w przypadku serwerów bazodanowych. Komunikacja odbywa się za pośrednictwem protokołu HTTP(S), a każde wysyłane żądanie zawiera kryptograficzną sygnaturę. Programista zwykle nie musi znać niskopoziomowych szczegółów działania tego interfejsu, ponieważ może wykorzystać wygodne, wysokopoziomowe API używając AWS CLI lub pakietów AWS SDK.
Jednak w niektórych zastosowaniach pojawia się potrzeba użycia innej bazy danych, a to zwykle oznacza konieczność przechowywania danych dostępowych gdzieś w „otchłani” naszej aplikacji. Kiepskim pomysłem jest zapisanie ich bezpośrednio w kodzie funkcji Lambda, co często oznacza, że trafią one później do repozytorium Git. Lepszym rozwiązaniem może być wykorzystanie zaszyfrowanych zmiennych środowiskowych Lambdy, a jeszcze lepszym – użycie usługi AWS Secrets Manager. Pozwala ona na bezpieczne przechowywanie haseł, kluczy dostępowych do API oraz innych poufnych informacji. Programista może łatwo pobrać takie dane w kodzie funkcji Lambda wywołując odpowiednią metodę z pakietu AWS SDK.
Jeśli nasza aplikacja korzysta z serwera bądź klastra bazodanowego stworzonego za pomocą usługi Amazon RDS, możemy skorzystać z uwierzytelniania IAM [7]. Po odpowiednim skonfigurowaniu bazy danych oraz roli IAM przypisanej do funkcji Lambda, jednym wywołaniem metody z AWS SDK pobieramy tymczasowy, ważny przez 15 minut token dostępowy, którego następnie używamy zamiast hasła w standardowej procedurze nawiązywania połączenia z bazą. Wymagane jest, aby było to szyfrowane połączenie SSL, co dodatkowo podnosi poziom bezpieczeństwa rozwiązania. Należy jednak pamiętać o pewnych ograniczeniach – np. w przypadku silnika MySQL możliwe jest nawiązanie w ten sposób maksymalnie 200 nowych połączeń na sekundę.
Podsumowanie
Warto pamiętać, że wybór modelu serverless nie zwalnia nas całkowicie z konieczności zajmowania się sprawami związanymi z bezpieczeństwem, jednak wykorzystując narzędzia i usługi dostępne w chmurze AWS możemy zdecydowanie ułatwić sobie to zadanie. Szczegółowy opis wszystkich możliwych zagrożeń spotykanych w tej architekturze oraz sposobów przeciwdziałania im, to materiał wystarczający na napisanie co najmniej jednej opasłej księgi.
Niniejszy artykuł porusza tylko wybrane zagadnienia i jest dobrym punktem wyjścia do dalszego pogłębiania wiedzy na ten temat. Zachęcam do przejrzenia materiałów uzupełniających, a także objerzenia nagrania z prelekcji zatytułowanej „Securing enterprise-grade serverless apps”, na podstawie której powstał ten artykuł.
Materiały uzupełniające
- Amazon Web Services, Inc., Security Overview of AWS Lambda. An In-Depth Look at Lambda Security.
- Auth0, Inc., JSON Web Token Introduction
- The OWASP Foundation, OWASP Serverless Top 10
- Amazon Web Services, Inc., Firecracker
- Yuval Avrahami, Gaining Persistency on Vulnerable Lambdas
- Amazon Web Services, Inc., Using IAM Policy Conditions for Fine-Grained Access Control
- Amazon Web Services, Inc., IAM Database Authentication for MySQL and PostgreSQL