What is Unified Namespace? A practical guide


Digital transformation and the need for better data integration
In the age of Industry 4.0, many organizations still struggle with a simple question: what is Unified Namespace, and how can it connect IT systems (ERP, BI, cloud analytics) with OT environments (machines, PLCs, SCADA, sensors)?
In many factories, data lives in separate tools and spreadsheets. One team sees “machine stopped,” another sees “production running,” and someone spends hours reconciling reports. This spaghetti architecture—point-to-point integrations, silos, and incompatible protocols—slows data flow, reduces visibility, and increases maintenance costs. That’s why data management and data governance matter more than ever.
A Unified Namespace (UNS) changes the game: it creates a shared, real-time data model that becomes a single source of truth across the organization. Instead of building yet another integration, systems publish and subscribe to the same structured data—making information easier to access, reuse, and scale.
Keep reading if you want to see how UNS turns scattered signals into one consistent, business-ready view of operations.
This guide is for plant leaders, OT/IT architects, and data teams building scalable IT/OT integration.
UNS in 60 Seconds: key takeaways
- What is Unified Namespace in one sentence: UNS is a real-time shared data model (often on an MQTT broker) where OT and IT publish/subscribe to structured data as a single source of truth.
- The Problem: the “spaghetti architecture” (point-to-point integration) creates technical debt and prevents fast scaling of the digital initiatives (including AI adoption).
- The Solution: an Unified Namespace (UNS) is an approach to the digital architecture. It acts as a central data broker where all smart assets publish data and all applications subscribe to it, leveraging a unified namespace architecture as the structural approach to simplify integration and enable real-time data access.
- Key Technology: MQTT is the standard transport protocol; Sparkplug B or standardized JSON defines the structure.
- Strategy: don’t rip and replace. Build the UNS alongside existing systems (Brownfield-first approach).
- Governance: governance, naming conventions, security (ACLs), and robust data management and data governance practices are more important than the software you buy.
- Outcome: real-time visibility, decoupling of hardware from software, and rapid integration of new tech (AI, Analytics).
What is a Unified Namespace?
Unified Namespace (UNS) is an architectural concept, not a specific piece of software. It is a consolidated abstraction of your manufacturing business structure, events, and process data, accessible in real-time.
In a traditional ISA-95 stack, data moves linearly: Sensor -> PLC -> SCADA -> MES -> ERP. This creates latency and silos.
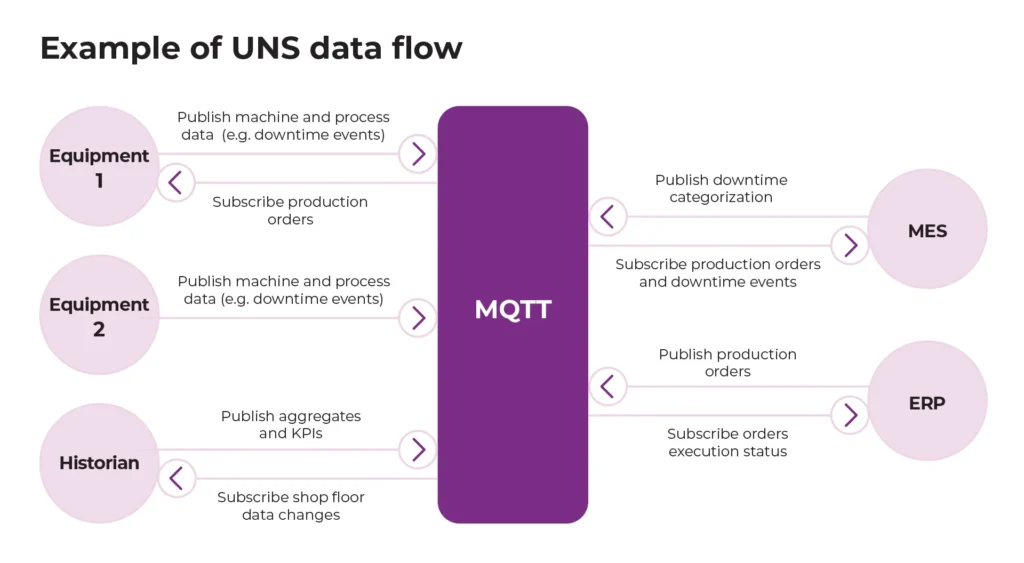
In a UNS architecture, the structure is hub-and-spoke. The UNS is the hub (usually an MQTT broker). Every node (Edge Gateway, MES, ERP, Cloud Analytics) is a peer. They produce data to the namespace and consume data from it.
In simple terms: the Unified Namespace is like the central nervous system of the factory: a single point of live, contextual data that connects every machine, system, and decision. By centralizing and standardizing the data, the UNS improves decision-making by making information accessible and consistent for all users and systems. Additionally, the UNS enhances communication between Operational Technology (OT) and Information Technology (IT), boosting operational efficiency across the organization.
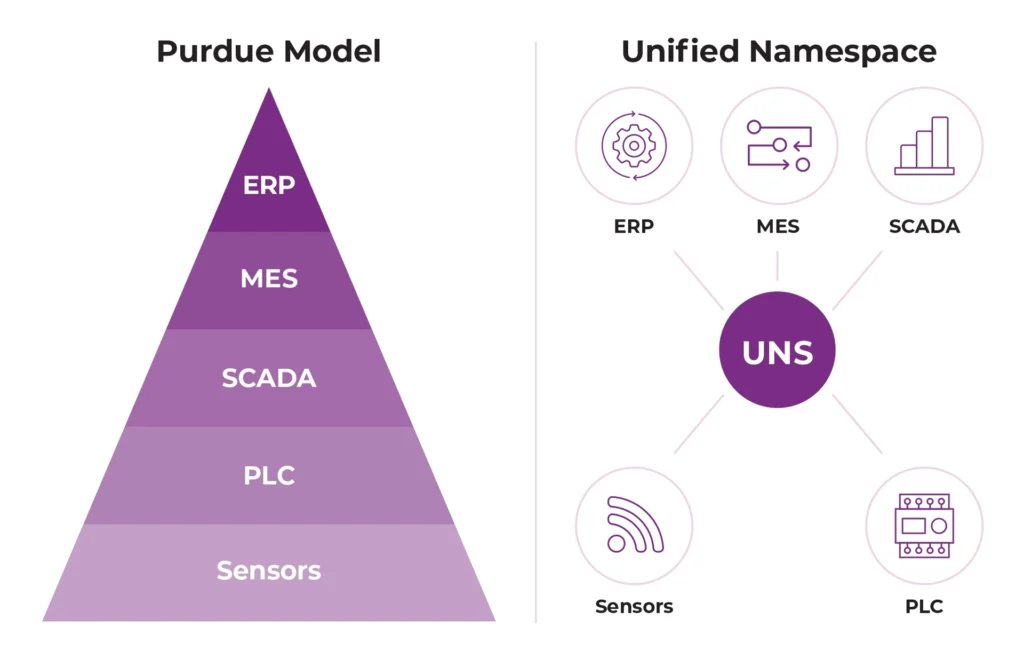
What is the difference between Unified Namespace and Purdue model?
The Purdue model is a factory “pyramid.” It used to be the standard design pattern for industrial data flow, where data moves step by step upward (machine → SCADA → MES → ERP), so it’s often not real-time and parts of the data get delayed or reshaped along the way.
Unified Namespace is different. It represents a modern design pattern for data integration and is an example of an event-driven architecture (EDA). If you ask what is the key idea: unified namespace (UNS) is a shared place (usually a broker) where systems publish real-time data once, and other systems subscribe to it. So is unified namespace basically one consistent stream of the data from the shop floor, available in real time, which supports digital transformation by reducing “spaghetti” integrations and keeping the data and context aligned across apps.
Why UNS suits multi-site enterprises
- Single Source of Truth: the current state of the business is always available at a known topic address, providing a unified and consistent view across the entire organization.
- Decoupling: you can swap out a SCADA system without breaking the ERP integration, provided the new SCADA publishes to the same topics.
- Edge to Cloud: it bridges the gap between high-frequency OT data and high-latency IT/Cloud systems by organizing and structuring data in a way that reflects the structure and events of your business.
How UNS differs from common alternatives
- Point-to-point integrations: tight coupling. Every new consumer needs a new connection and mapping. Fragile and slow to scale.
- Historians: great for time-series storage and analysis, but typically not a live integration backbone. they store data; they don’t solve standardization and decoupling by themselves. However, you can integrate a data historian into the UNS to centralize access and enable unified data flows.
- Data lakes / warehouses: good for long-term analytics and enterprise reporting, but often too slow and batch-heavy for real-time operations and event-driven use cases. Integrating a data lake or warehouse into UNS allows unified access to both historical and real-time data within a single platform.
UNS suits multi-site manufacturing because it provides a consistent, reusable contract from edge to cloud, enabling a digital thread across plants. If you want a concrete example of the data from production being standardized and reused across multiple consumers, check this case: Unified Namespace example in FMCG.
Outcomes and benefits of UNS
A well-designed Unified Namespace (UNS) delivers business value quickly—especially when you can onboard new dashboards, analytics tools, or MES apps without rebuilding PLC-to-app integrations every time.
Core benefits (most common)
- Single source of truth: everyone reads the same operational meaning—not just raw tags—so teams stop arguing which number is “correct.”
- Decoupling: producers publish once, consumers subscribe as needed. You can change or replace one system without breaking the others.
- Fewer integrations: instead of many fragile point-to-point connections, you get one publish path and many subscribers.
- Faster onboarding: new consumers (dashboards, MES, BI, analytics, AI) connect through subscription, not custom wiring.
Operational wins (where it shows up first)
- Faster OEE and downtime reporting: standardized events and states improve classification and reduce manual reconciliation.
- Shorter changeover improvement loops: consistent, real-time signals make it easier to spot patterns and remove bottlenecks.
- Better diagnostics and lower MTTR: maintenance teams get clearer context (what happened, when, and where), speeding up troubleshooting.
- Enhanced data management and analytics: UNS organizes and unifies real-time data from multiple systems, enabling faster analysis and better decisions. For more, see: How Unified Namespace breaks down data silos in industrial data management.
Brownfield reality – you don’t “rip and replace” PLC programs to start. You standardize what you can at the edge, publish safely, then improve semantics over time.
Prerequisites checklist
Before you start, clarify what is Unified Namespace for your plant: scope, owners, and consumers.
Must-have:
- Asset inventory (PLCs, gateways, SCADA/MES/historian)
- Draft naming convention (ISA-95 hierarchy)
Nice-to-have (makes scaling easier):
- Network segmentation + OT DMZ for broker access
- Time sync (NTP at minimum)
- PKI lifecycle plan (cert rotation)
- Change management (RACI, windows, rollback)
- Retention policy (broker vs historian vs lake)
Reference Architecture: how data flows
The physical implementation usually follows a tiered approach to ensure security and reliability.
The Data Flow
- Layer 0-1 (Edge): PLCs and sensors act as data producers, generating data points that are collected by an Edge Gateway (e.g., Kepware, Ignition Edge). The gateway converts native protocols (EtherNet/IP, Modbus, PROFINET) to MQTT. This is where a first unification and standardization of data points from various data sources occurs.
- Layer 2-3 (Site): edge gateways publish these unified data points to a Local MQTT Broker (Site UNS).
- Layer 4-5 (Enterprise/Cloud): the local broker bridges specific topics to an Enterprise MQTT Broker (Global UNS) or Cloud, integrating data sources from multiple sites into a single unified namespace for enterprise-wide access and analysis.
High availability and DMZ patterns
- Single plant HA: broker cluster (active/active) or primary/secondary with failover.
- OT DMZ: place brokers or broker endpoints in DMZ; keep PLC networks isolated.
- Multi-site:
1.Local broker per plant for resilience (preferred)
2. Optional MQTT bridge to a regional/central broker for enterprise consumers
3. Multi-region replication for cloud/enterprise scale
Multi-site rule of thumb
Keep data publishing local to each plant for uptime and reliability. Replicate upstream; don’t force every edge device to reach the cloud.
How to implement an Unified Namespace (UNS): topic and data design
Designing topics: the rules that prevent chaos
This is the most critical step. If your topic structure is messy, your data lake becomes a data swamp.
Model with ISA-95/ISA-88 and domain-driven design
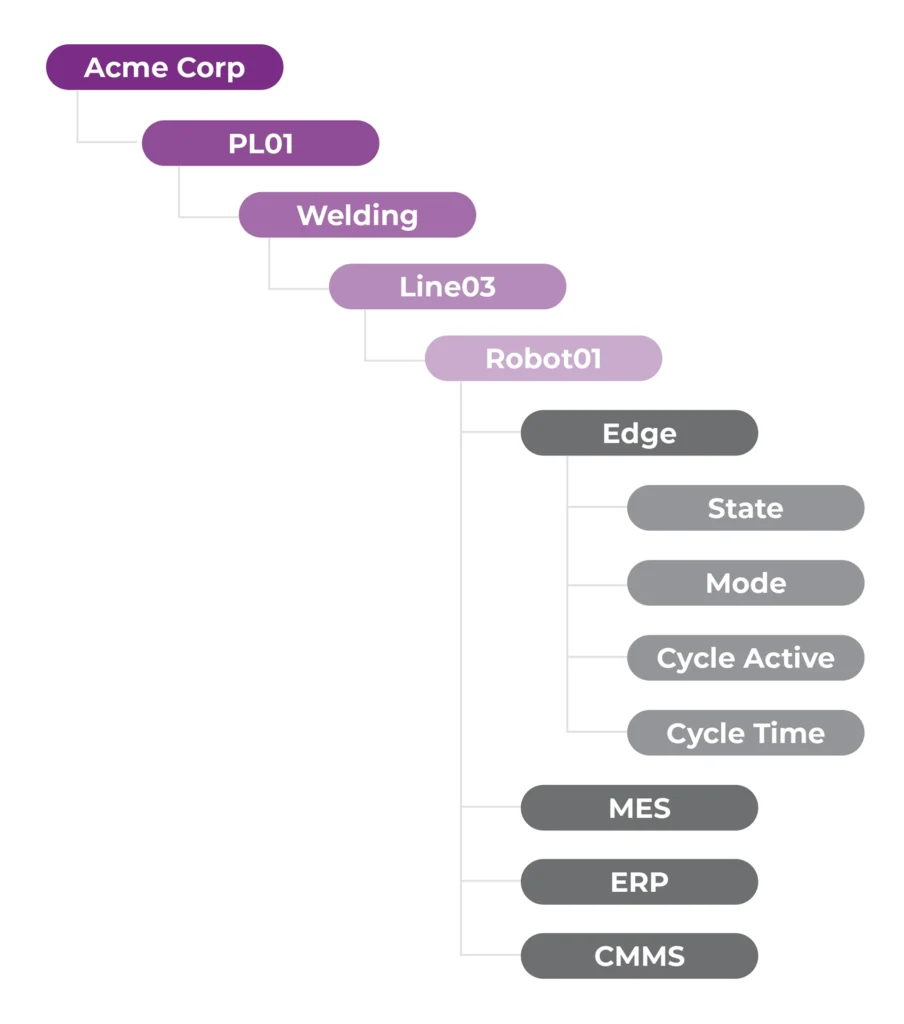
Define your core hierarchy using ISA-95 (enterprise/site/area/line/cell) and use ISA-88 concepts where batch/process applies (unit/procedure/phase).
The base hierarchy can be expanded by domain-driven elements: topics represent business-relevant objects/systems (equipment, orders, quality events, MES, ERP), not random PLC memory addresses.
Base topic pattern
The standard hierarchy for unified namespace is: Enterprise / Site / Area / Line / Cell / Asset
| Level | Example | Description |
| Enterprise | acme | The global organization |
| Site | PL-WAW | A specific physical facility |
| Area | packaging | A production zone |
| Line | L03 | A sequential production line |
| Cell | cell-02 | A logical grouping of equipment |
| Asset | packer | The physical device |
Good vs bad MQTT topic examples
Good (meaningful, consistent):
prod/acme/PL-WAW/packaging/L3/cell-02/packer-01/speed
prod/acme/PL-WAW/packaging/L3/cell-02/packer-01/jam_detected
prod/acme/PL-WAW/packaging/L3/cell-02/packer-01/mode
Bad (opaque, unstable, or too PLC-centric):
PLCWAW/DB12.DBW4
factory1/line3/tag123
prod/packer01/speed/fast
Sparkplug B vs native MQTT + JSON
- Sparkplug B: an open specification that defines the topic structure and payload.
- Pros: plug-and-play interoperability; defines „Birth” (I am online) and „Death” (I am offline) certificates automatically.
- Cons: can be rigid; requires Sparkplug-aware brokers/clients for full benefits.
2) Native MQTT + JSON: Custom structure.
- Pros: maximum flexibility; human-readable.
- Cons: you must build your own governance and state management (Birth/LWT).
![Side-by-side UNS/MQTT example. Left: topic format company/site/area/line/machine/tag with example Acme/PL01/Welding/Line03/Robot01/Speed and a JSON payload containing value: 42.7, unit: mm/s, and a timestamp. Right: Sparkplug B topic format spBv1.0/group_id/message_type/edge_node_id/[device_id] with an example topic and a payload showing seq, timestamp, and a metrics array including the metric name “Speed,” value 42.7, type “Float,” and unit mm/s](https://cdn-ttpsc.ttpsc.com/content/uploads/2025/12/TT-PSC-TT-PSC-GRAPHIC-UNS-MQTT-2a-1024x450.webp)
Recommendation: Use Sparkplug B if your ecosystem (MES/SCADA/Gateways) supports it natively. Use Native MQTT with strictly governed JSON schemas for custom app integration or legacy constraints.
Unified Namespace (UNS) style guide
Write a one-page style guide and enforce it.
Naming rules
- Lowercase topics (avoid case issues).
- Separator: / for MQTT topics; – inside IDs; avoid spaces.
- Stable IDs: site and asset must match CMMS functional locations where possible.
- Avoid free text in topic names; put details in payload fields.
Versioning rules
- Topic structure should be stable.
- Payload schema changes use semantic versioning (MAJOR.MINOR.PATCH).
- Breaking changes require a new version and compatibility window.
Units and timestamps
- Always include uom (unit of measure).
- Timestamp in UTC ISO-8601.
- Add a quality flag.
Mapping table – PLC tags to standardized topics and payloads
| Source (PLC/SCADA) | Raw tag | Standard topic | Payload signal | uom |
| PLC Packer01 | DB20.Speed | prod/acme/PL-WAW/packaging/L3/cell-02/packer-01/speed | speed | bpm |
| PLC Packer01 | JamBit | …/jam_detected | jam_detected | bool |
| SCADA | ModeText | …/mode | mode | enum |
Data payloads and governance
The topic tells you where the data is. The payload tells you what it is.
In the implementation of a Unified Namespace (UNS), data governance and data management are essential to ensure payload quality and compliance with data schemas. Establishing strong governance and management practices ensures the integrity, reliability, and security of information in real-time industrial environments.
Payload requirements
Every payload must include:
- Value: the actual data point (e.g., 45.2).
- Timestamp (ts): ISO 8601 or Unix Epoch. The time the event happened, not when it was received.
- Quality (q): good, bad, uncertain.
- Unit of Measure (uom): standardize this (e.g., always Celsius, never Fahrenheit).
- Semantic versioning: v field in payload
- Idempotency: include event IDs for events to avoid duplicates
MQTT behavior rules (reliability)
- QoS (Quality of Service):
- QoS 0 (at most once): fire and forget. Good for high-frequency data.
- QoS 1 (at least once): guaranteed delivery. Standard for most process data.
- QoS 2 (exactly once): high overhead. Avoid unless strictly necessary.
2) Retained Messages: enable this for state topics (e.g., Line/State). When a new dashboard connects, it instantly receives the last known state without waiting for a change. Usually used for state (last known value), not for high-rate telemetry.
3) LWT (Last Will and Testament): publish offline state on disconnect.
Recommendations for Quality of Service:
- Telemetry: QoS 0 or 1 (pick based on loss tolerance)
- Events: QoS 1 (at least once) + duplication handling
- Commands: QoS 1 or 2 (be careful; test thoroughly)
Schema first, always
If you publish without a schema, you’re creating future integration debt. A “working” UNS with undocumented payloads is just chaos with MQTT.
Security first: don’t ship an open broker
Security is not optional. Do not deploy an open port 1883.
Zero-trust basics
- TLS everywhere
- Mutual authentication (client certs preferred)
- Least privilege with MQTT ACL patterns
- Audit logging and traceability
- Separate dev/test/prod brokers (or at minimum separate listeners + strict ACLs)
ACL patterns
ACLs are Access Control List which allow to configure who is able to access particular data.
- Publishers can only write under their asset path
- Consumers can only read what they need
- No wildcard publish rights
Offline buffering and store-and-forward
- Edge gateways should buffer when broker is unavailable
- Use persistent sessions where appropriate
- Monitor queue depth and reconnect storms
Bridging between brokers
Use an MQTT bridge for multi-site replication:
- Plant broker is the source of truth for plant operations
- Central broker aggregates for enterprise use
- Filter and throttle what you replicate (don’t replicate everything)
If you want a security-aligned way to deploy MQTT in industrial environments, use an authoritative reference: OASIS published “MQTT and the NIST Cybersecurity Framework”, a guidance note that maps MQTT deployment practices to the NIST Cybersecurity Framework. It’s a solid external baseline for decisions around TLS, authentication, access control (ACLs), logging, and operational security governance—without tying you to any specific vendor.
Step-by-step implementation plan
| Phase 0: discovery (1–3 weeks per site) | |
|---|---|
| Goal | Understand assets, protocols, and consumers. |
| Steps | 1) Inventory assets, PLC types, protocols (OPC UA, Modbus, proprietary drivers). 2) Identify consumers: historian, MES, QMS, CMMS, analytics, cloud. 3) Pick 3–5 high-value signals/events per asset class. 4) Define the first namespace draft + payload template. |
| Acceptance criteria | – Asset hierarchy agreed (site/area/line/cell/asset IDs) – First topic pattern documented – Security approach chosen (certs, ACL approach) |
| Owners (typical) | OT lead, IT network/security, data/analytics lead |
| Phase 1: pilot one value stream (4–8 weeks) | |
| Goal | Prove value and patterns on one line/cell. |
| Deliverables | 1) Edge connector deployed 2) Broker deployed (non-production if needed) 3) Telemetry + events published 4) One consumer onboarded (e.g., downtime dashboard + historian integration) 5) Start documenting and executing test cases for robust quality and reliability checks (e.g. failover scenarios) |
| Acceptance criteria | – Data quality verified (timestamps, units, quality flags) – Consumer built without point-to-point to PLC – Basic monitoring in place |
| Phase 2: harden and standardize (4–6 weeks) | |
| Goal | make it repeatable. |
| Work items | 1) Lock naming conventions and topic structure manufacturing rules 2) Add schema validation + versioning policy 3) Define MQTT ACL templates + certificate lifecycle 4) Create onboarding runbook for new assets and consumers |
| Acceptance criteria | – Style guide published + enforced in CI/review – No new topics without an owner and schema – Dev/test/prod separation defined |
| Phase 3: scale to plant, then multi-site (8–20 weeks) | |
| Goal | Expand coverage and resilience. |
| Work items | 1) HA broker topology (cluster or primary/secondary) 2) Plant DMZ pattern implemented 3) Standard gateway images/configs 4) MQTT bridge to central broker (optional) 5) Observability: broker metrics, gateway health, lag, drop rates |
| Acceptance criteria | – Broker uptime target met – Onboarding time per asset drops each sprint – Cross-site topic consistency achieved |
| Phase 4: govern and evolve (ongoing) | |
| Goal | Keep it clean. |
| Work items | 1) Change board, deprecation windows, release notes 2) Quarterly cleanup: remove unused topics, retire versions 3) Security audits and certificate rotation drills |
| Acceptance criteria | – Breaking changes follow policy – Backward compatibility windows respected – Audits pass without “everyone is admin.” |
Tooling options
Choose tools that fit your constraints (brownfield, uptime, skills). Some of the decision criteria are mentioned below.
| Category | Options | Selection Criteria |
| MQTT Brokers | EMQX, HiveMQ, Mosquitto, VerneMQ | Scalability (# of connections), Clustering/HA, Bridging/replication support, Security options, Observability, Enterprise support. |
| Edge Gateways | Ignition Edge, Kepware, HighByte, in some cases even OPC UA | Protocol driver support (Siemens, Allen-Bradley, other – but also IT protocols: MQTT), Store-and-forward capability, manageability at scale (multi-plant) |
| Data Ops/Context | HighByte Intelligence Hub, Node-RED | Ability to model and transform data before publishing to the UNS. |
| Observability | Grafana, Prometheus, MQTT Explorer | Ease of visualization and alerting, audit trails. |
| Data sinks | Historians (such as CanaryLab Historian), data lakes / warehouses, stream processors | Ability to connect (e.g. support for MQTT), scalability, handling the data vs size performance and support on read/write, aggregation features, reporting support. |
There’s no easy recommendation and “the single best” tool. After initial due diligence, the best setup for your current landscape can be recommended.
KPIs and ROI
Track outcomes that matter:
- Integration Time: Time required to onboard a new machine.
- Data Accessibility: % of plant assets visible in the UNS.
- Engineering Hours Saved: Hours saved by not writing point-to-point scripts.
- MTTR (Mean Time To Recovery): Improved by faster diagnostics via the UNS.
Common pitfalls and remediations
Topic Sprawl:
- Symptom: random topics like temp_test_final_v2 appears in the UNS.
- Fix: strict ACLs that reject publishes to undefined topics. Registry of the topics with regular monitoring of the topics. Governance & owners of the topics.
Undocumented Payloads:
- Symptom: consumers break when a field name changes.
- Fix: use versioning and commonly accepted schemas.
Broker as Database:
- Symptom: trying to query historical data from the broker.
- Fix: Brokers move data: historians store data. Bridge the broker to a historian.
Mixing Dev and Prod:
- Symptom: test data polluting the production dashboard.
- Fix: use different root topics (e.g., /prod/acme/… vs /test/acme/…) or separate brokers.
Broker single point of failure (SPOF):
- Symptom: no data exchange and UNS update available on broker failure.
- Fix: HA clustering or primary/secondary + tested failover.
Over-modeling too early:
- Symptom: long time spent early on documentation of all possible standards. Prolonging discovery phase.
- Fix: start minimal, iterate with real consumers.
Governance and lifecycle
Keep governance lightweight but strict:
- Ownership & steering: clear owners of particular parts of the hierarchy/topics; regular governance meetings to monitor and decide on changes. Strong data governance practices are essential to maintain data quality, security, and compliance within the unified namespace.
- Versioning policy: semantic versioning; breaking changes require a new major.
- Deprecation notices: publish release notes and target removal dates.
- Backward compatibility window: e.g., 90–180 days for major versions.
- Change windows: align with OT maintenance windows.
- Doc templates: per topic/payload: owner, purpose, schema link, examples, QoS, retention, consumers.
Unified Namespace (UNS) rollout checklist
- Asset inventory completed and CMMS IDs aligned
- Broker HA pattern selected and tested
- Namespace style guide published (topics + IDs)
- Payload schema rules defined (JSON Schema + versioning)
- QoS/retained/LWT standards agreed
- MQTT ACL templates created and validated
- Edge gateway template built (buffering, reconnect behavior)
- Pilot line publishing telemetry + events
- One real consumer onboarded via subscription
- Historian integration validated (timestamps/quality)
- Monitoring dashboards and alerts live
- PKI and certificate lifecycle defined
- Network zones/DMZ pattern approved
- Time sync verified (NTP/PTP)
- Change board and deprecation process active
Conclusion
Implementing a unified namespace is a paradigm shift from “integration” to “modeling.” It moves you away from fragile point-to-point connections toward a resilient, event-driven architecture—and answers the question: what is Unified Namespace in practice.
If you’re serious about how to implement a Unified Namespace (UNS), start small: pick one line, run a workshop, publish a few high-value signals and events, and prove a consumer can onboard without a new PLC integration. Then harden security, standardize, and scale plant-by-plant with governance.
Next step: Don’t try to architect the whole enterprise on paper. Start with one line. Convene a workshop to agree on the naming convention for that line, deploy a broker, and get data flowing. Scalability comes from the standard, not the software.
Glossary
UNS: Unified Namespace
IIoT: Industrial Internet of Things
MQTT: pub/sub messaging protocol
QoS: Quality of Service (delivery guarantee levels)
ACL: Access control list for topic permissions
DCS: Distributed Control System
MES: Manufacturing Execution System
CMMS: Computerized Maintenance Management System
OEE: Overall Equipment Effectiveness
ISA-95/88: Manufacturing and batch modeling standards
PKI: Public Key Infrastructure (certs, trust)
HA: High availability
Walker Reynolds: expert and thought leader in Unified Namespace (UNS) and industrial automation, recognized for their influence on the evolution of UNS architecture and for promoting and explaining this technology within the industrial sector.