High Availability w aplikacjach IoT


Współczesne serwisy internetowe odpowiadają na miliony zapytań użytkowników. Wszystkie one działają w środowiskach klastrowych. Obsługa wielu zapytań wymaga znacznych zasobów, takich jak czas procesora (CPU) oraz pamięć RAM. Każde połącznie do serwera generuje jego dodatkowe obciążenie. W takiej sytuacji jeden serwer wymagałby ogromnych ilości zasobów, a prawo Moor’a już się nie sprawdziło. Aby temu zaradzić potrzebujemy wielu serwerów, które obsługują zapytania użytkowników.
Aplikacje webowe (w tym także IoT) używają protokołu HTTP(S), który działa na zasadzie: żądanie-odpowiedź. Gdy użytkownik otwiera stronę, lub wywołuje akcję, zostaje wysłane żądanie do serwera. Na każde żądanie użytkownika serwer musi przygotować odpowiedź. Każda odpowiedź musi zostać w odpowiedni sposób przeprocesowana, a to stanowi główne kryterium estymacji ilości zasobów serwera – żądania mogą być różne, od danych statycznych jak style CSS lub obrazy, po skomplikowane jak pobieranie danych z bazy, filtrowanie lub wyliczanie pewnych współczynników.
Czas pomiędzy stworzeniem żądania a uzyskaniem odpowiedzi nazywamy latency. Oczywistym jest, że dążymy do jak najmniejszego latancy. Pierwszy problem, który może się pojawić to przepełnienie serwera żądaniami do takiego stopnia, że nie jest w stanie odpowiadać w akceptowalnym czasie (lub w ogóle). W celu utrzymania niskiego latancy wykorzystuje się środowiska klastrowe. Klastry pozwalają stosunkowo łatwo budować niezawodne, skalowalne oraz elastyczne serwisy. Oprócz tego możliwym jest uruchomienie High Availability (ang. wysoka dostępność) – pozwala to zapewnić ciągłość pracy aplikacji, nawet jeśli serwer jest niedostępny. Gartner obliczył, że średni koszt każdej minuty przestoju wynosi $5 600.
Na dłuższą metę klaster pozwala zaoszczędzić pieniądze poprzez zmniejszenie ilości i czasu przestojów. Próg wejścia jest nieco wyższy z powodu nadmiarowości sprzętu – każda część klastra to działający serwer, co znacznie ułatwia efektywne zarządzanie serwisami. Użytkownicy będą częściej wracać, jeśli aplikacje i serwisy są zawsze dostępne, szybkie i pozbawione błędów. Firmom dostarczającym serwisy pozwala to zmniejszyć nie tylko przestoje ale też czas i pracę inżynierów odpowiedzialnych za przywrócenie systemu.

Jak działają klastry
Klaster to wiele serwerów, na których działa dokładnie ta sama aplikacja z dokładnie taką samą konfiguracją. Wszystkie serwery w klastrze pracują wspólnie, co przekłada się na wysoką dostępność, niezawodność i skalowalność. Każdy serwer może obsłużyć żądania, dzięki czemu cały system lepiej radzi sobie z obciążeniem. Z perspektywy użytkownika nic się nie zmienia – ciągle używa tego samego adresu URL lub IP w celu połączenia. Żądanie jest przekierowywane do odpowiedniego serwera na podstawie wybranego algorytmu równoważenia obciążenia. Istnieje wiele różnych algorytmów i wybór konkretnego zależy od wymagań i danego przypadku użycia.
Do najbardziej popularnych należą:
- Roundrobin – serwery wybierane są turami, a obciążenie jest równomiernie rozłożone
- Least connection (ang. najmniej połączeń) – serwer z najmniejszą liczbą połączeń obsługuje żądanie
- Source (ang. źródło) – każdy użytkownik (ten sam adres IP) będzie przekierowywany do tego samego serwera, który został przydzielony przy pierwszym połączeniu.
- Uri – użytkownicy używający tego samego adresu uri (niezależnie, czy jest to lewa, czy prawa strona znaku zapytania) będą kierowani do tego samego serwera
- Hdr – podobny do Uri, ale używa nagłówków zapytania HTTP do wybory serwera
Bardzo popularne jest wybieranie serwera ze względu na geolokalizację – żądanie dostanie serwer, który jest najbliżej użytkownika (na podstawie lokalizacji danego adresu IP).
Podsumowując:
- Wykorzystywany jest algorytm balansowania obciążenia – używany przez Load balancer
- Load balancer przekierowuje połączenia do serwerów w klastrze, co gwarantuje nieprzerwane działanie serwisów oraz replikację sesji
- Serwery obsługują konkretne żądania użytkowników
Wydaje się to koncepcyjnie proste, a zarazem bardzo skuteczne. Problem zaczyna się od strony implementacyjnej. Dlatego do budowania klastrów stosuje się wiele narzędzi pomagających nimi zarządzać.
Czym jest High Availability?
Skutki wyłączenia systemu mogą być katastrofalne. To nie tylko koszty poniesione przez przedsiębiorstwo, ponieważ nie może ono zarabiać na działającym systemie, ale także ogromny nakład pracy, aby postawić system z powrotem na nogi. Istnieje wiele mniej lub bardziej spodziewanych przyczyn zaprzestania działania serwera, to może być awaria systemu, brak prądu, błąd aplikacji i wiele innych.
Aby zapobiec nieoczekiwanym przestojom należy użyć środowisk klastrowych. Jeśli jeden z serwerów nie jest w stanie obsługiwać żądań, ruch może zostać przekierowany do innych serwerów, które nadal działają. Taki scenariusz nazywa się High availability. Bez znaczenia co stanie się z serwerem, zawsze dostępne są inne, które mogą przejąć obsługę żądań. Nadmiarowość pozwala klastrowi być zawsze dostępnym, nawet gdy pojawi się problem – mało prawdopodobnym jest, że wszystkie węzły klastra będą niedostępne.
Amazon zapewnia 99,999% (także nazywane „pięcioma dziewiątkami”) dostępności dla systemów reagowania kryzysowego. Dlaczego potrzebujemy aż trzech dziewiątek po przecinku? Czy 99% nie będzie wystarczające? Otóż nie, dostępność na poziomie 99% oznacza ~87 godzin przestojów w ciągu roku, czyli 14 minut na dzień! Dla systemów, które działając całą dobę to zdecydowanie z dużo.
Osiągnięcie High Availability (lub po prostu HA) jest zdecydowanie łatwiejsze przy użyciu odpowiednich narzędzi. Najważniejszy z nich jest wspomniany Load balancer. To przewodnik, który pokazuje każdemu żądaniu drogę do serwera gdzie zostanie rozpatrzone. Load balancer dokładnie wie, ile żądań przechodzi do klastra oraz ile z tych żądań każdy z serwerów obsłużył. Pozwala to równoważyć obciążenie na wszystkie dostępne serwery. Load balancer zna także kondycję wszystkich serwerów np. na podstawie długości obsługi podobnych żądań, wie które serwery są niedostępne i może przekierować użytkowników na wciąż działające serwery. To trochę tak, gdy mechanik oferuje samochód zastępczy na czas naprawy.

High Availability w ThingWorx
High Availability w ThingWorx zostało zaprezentowane w wersji 8.0. Pozwala ono na stworzenie wielu instancji serwera ThingWorx i połączenia load balancera. Zawsze dostępny jest jeden tzw. Master serwer, który obsługuje żądania. Inne serwery pełnią funkcję pomocników, którzy czekają, aż serwer główny przestanie działać (z jakiejkolwiek przyczyny), aby wejść na scenę i dokończyć show. To podejście nazywa się Active-Passive. Klaster ma wiele węzłów, ale tylko jeden, główny, jest aktywny w danym momencie. Pomaga to w budowaniu High Availability, ale nie jest zbyt pomocne przy skalowaniu klastra. Dodawania nowych węzłów zwiększa dostępność systemu – trochę jak dodawanie dziewiątki po przecinku.
Współczesne aplikacje IoT opierają się na łączności. Niezwykle ważnym jest, aby serwer był dostępny, ponieważ w takich aplikacjach najważniejsze są dane. Urządzenia, które nieustannie zbierają dane nie zawsze są w stanie przechowywać je przez dłuższy czas, a jeszcze rzadziej mogą te dane przetwarzać w wartość.
Aplikacje działające na platformie ThingWorx są krytyczne dla całej infrastruktury – jest to centralna baza danych, która bez przerwy analizuje dane i może do nich stosować modele uczenia maszynowego. Dzięki temu urządzenia końcowe mogę być kontrolowane na podstawie obecnego stanu (np. rozpoczynać nawadnianie roślin, gdy ziemia jest zbyt sucha) lub przewidywanych działań (np. optymalizacja farm wiatrowych na podstawie prognoz pogody). Przez niedostępność systemu ThingWorx, żadne z powyższych nie może się zadziać. Jest to główny powód, dla którego warto rozważyć klastry pracujące w trybie Active-Passive.
High Availability Overview
ThingWorx używa oprogramowania Apache Zookeeper do zarządzania klastrem. Zookeeper pozwala na:
- Zarządzanie konfiguracją
- Wybór lidera (głównego serwera)
- Synchronizację
- Usługę nazewnictwa – łatwe dodawanie nowych węzłów
- Zarządzanie całym klastrem
Dzięki zastosowaniu oprogramowania Zookeeper, dodawanie nowych serwerów do klastra jest niesamowicie proste. Wszystko, co jest potrzebne, to nowy serwer, który wystarczy dołączyć do klastra. Bez ponownych uruchomień i przestojów. Wystarczy skonfigurować serwer offline, przetestować aplikację i przekazać do Zookeepar’a, że mamy nowy węzeł. Zookeeper automatycznie włączy serwer do klastra i zapewni, że konfiguracja jest taka sama na wszystkich serwerach.
Zazwyczaj pod HA potrzebujemy jeden węzeł główny – wybierany przez Zookeeper’a podczas uruchamiania klastra oraz 2 lub więcej węzłów pomocniczych – zawsze gotowych, ale nie obsługujących żądań. Nadmiarowość serwerów zawsze należy skonfrontować z wymaganiami oraz konkretnymi przypadkami użycia.
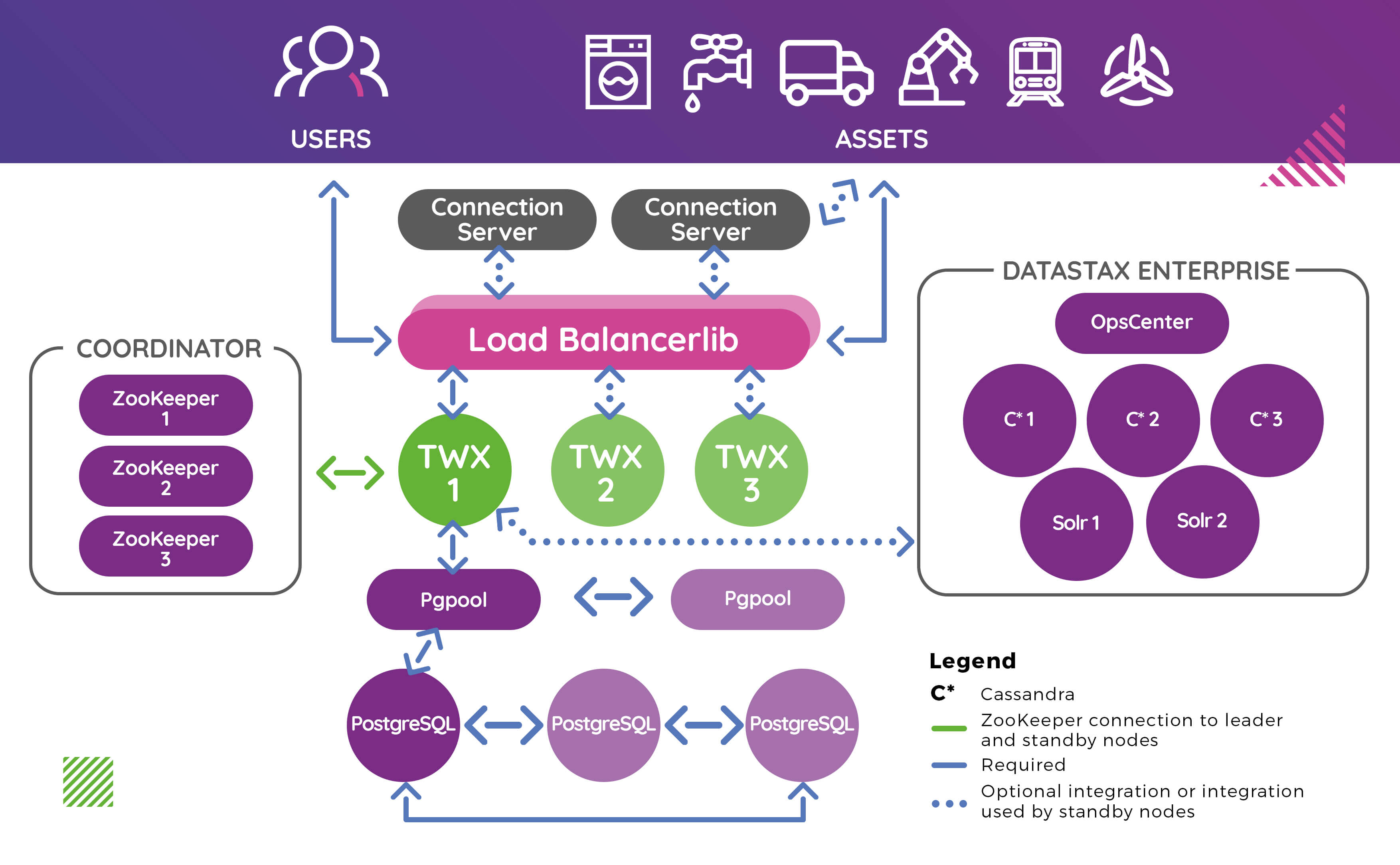
Na diagramie widać, że wszystkie połącznia trafiają do load balancera. Aplikacje klienckie oraz urządzenia nie łączą się do platformy bezpośrednio. To pozwala na przekierowywanie ruchu do aktualnie aktywnej instancji systemu ThingWorx. Gdy węzeł z powodu błędu zostaje wyłączony, load balancer automatycznie przekieruje ruch do innego węzła, który od tej pory będzie węzłem głównym.
Beyond High Availability
wykowsCelem poradzenia sobie ze wzmożonym ruchem lub wysokim obciążenie potrzebne jest inne podejście: klaster w trybie Active-Active. Taka opcja została dodana do wersji 9 platformy ThingWorx. Węzły, zamiast czekać, mogą aktywnie brać udział w obsłudze żądań. Klastry zapewniają nie tylko HA, ale także ułatwiają skalowanie horyzontalne. Taki typ skalowania pozwala na łatwiejsze dostarczenie nowych zasobów do klastra. Zamiast wymiany sprzętu w działającym serwerze, co oczywiście powoduje jego wyłączenie oraz przestój, dodawany jest nowy serwer, który jak wspomniano, może być przygotowany wcześniej i dodany do klastra. Planowanie zasobów produkcyjnych jest wyzwaniem, ale zdecydowanie łatwiejszym w środowiskach klastrowych.
Skalowalność aplikacji można mierzyć ilością żądań, która może być równocześnie obsłużona przez serwer. Punkt krytyczny znajduje się tam, gdzie aplikacja nie może efektywnie obsłużyć nowych żądań. Taki punkt często nazywa się limitem skalowalności. Warto wspomnieć, że zdecydowanie łatwiej jest dwukrotnie zwiększyć ilość żądań, dodając drugi serwer, niż zrobić to samo, zwiększając zasoby jednego serwera. Dzięki platformie ThingWorx 9 możliwe jest budowanie skalowalnych rozwiązań IoT, które mogą obsługiwać setki tysięcy urządzeń.
Jeśli potrzebujesz pomocy we wdrażaniu nowych lub rozbudowywaniu istniejących rozwiązań w oparciu o ThingWorx skontaktuj się z nami.