Machine Learning & ThingWorx vs COVID-19

Rozwój sztucznej inteligencji, a wraz z nią uczenia maszynowego, nabrał w ostatnich latach dużego rozpędu. Ciągłe dążenie do zwiększenia mocy obliczeniowej komputerów dało możliwość wykorzystania algorytmów oraz aparatu matematycznego stworzonych w drugiej połowie XX wieku na niespotykaną dotąd skalę. Mając w perspektywie rychłe nadejście komercyjnego komputera kwantowego, można powoli zacząć obawiać się scen rodem z filmów z Arnoldem Schwarzeneggerem w tytułowej roli Terminatora. Nie wybiegając jednak za daleko w przyszłość, a skupiając się na teraźniejszości, postanowiłem sprawdzić, jakie możliwości daje dostępna dzisiaj technologia oraz czy można wykorzystać ją w predykcji rozprzestrzeniania się choroby COVID-19.
Czym jest uczenie maszynowe?
W sieci można znaleźć wiele definicji uczenia maszynowego: ideologiczne, ściśle matematyczne, a nawet i filozoficzne. Próbując samodzielnie zdefiniować to pojęcie, stwierdziłem, że najlepiej skupić się na porównaniu uczenia maszynowego z klasycznym programowaniem.

1) Porównanie uczenia maszynowego z tradycyjnym programowaniem
Pomijając wszelakie metodologie wytwarzania oprogramowania (obiektowe, strukturalne, funkcyjne itp.), większość z nas wie i rozumie, na czym polega tradycyjne programowanie: posiadając dane wejściowe oraz stosując odpowiedni do rozwiązania danego problemu algorytm, otrzymujemy rezultaty – dane wyjściowe.
Przykładowo: algorytmy używane w bankowości są z góry zdefiniowane, a dzięki ich dokładnej implementacji nie martwimy się, czy przelew internetowy, który wyślemy, na pewno dojdzie do odbiorcy i saldo na naszych rachunkach będzie się zgadzać.

2) Przykładowy algorytm w programowaniu tradycyjnym
Wygląda więc na to, że tworząc poprawny algorytm, jesteśmy w stanie rozwiązać dowolne zadanie, i jest to całkowita prawda. Problem pojawia się jednak, kiedy stworzenie takiego algorytmu jest nietrywialne, a czasami wręcz niemożliwe do zrobienia.
Dobrym przykładem takiego problemu (pozostając w strefie finansów) byłby algorytm przewidujący z wyprzedzaniem dokładne ceny akcji spółek na giełdzie – nie ma tutaj sztywnych ram i zasad, które opisywałyby zachowanie kursu akcji. Na ostateczną cenę wpływają setki, jak nie tysiące, różnych zmiennych, niekiedy pojedyncze nieprzewidywalne decyzje prezesów czy choćby katastrofy naturalne. Fizycznie niemożliwe jest zaprojektowanie oraz zaimplementowanie takiego algorytmu, który w sposób dokładny rozwiązywałby ten problem. Co więcej – nawet jeśli chcielibyśmy podjąć próbę stworzenia algorytmu, który chociaż w sposób przybliżony określałby zachowanie przyszłej ceny danych aktywów (np. zwracał informację czy jutro cena wzrośnie czy zmaleje) – byłoby to bardzo karkołomne zadanie, wymagające ogromnej wiedzy domenowej z dziedzin maklerskich oraz bardzo skomplikowanych zależności wynikających z mnogości zmiennych, które wpływałyby na wynik.
Z pomocą przychodzi tutaj właśnie uczenie maszynowe, czyli poniekąd odwrócenie dziedziny problemu – zamiast wyliczać konkretne wartości wyjściowe przy pomocy określonego algorytmu (tak, jak ma to miejsce w tradycyjnym programowaniu), spróbujmy znaleźć algorytm, który w sposób możliwie najdokładniejszy odwzoruje znane nam dane wejściowe na dane wyjściowe. Genialne w swojej prostocie podejście poparte solidnymi równaniami matematycznymi otwiera nieograniczone wręcz możliwości rozwiązywania problemów, które byłyby trudne, a w większości przypadków niewykonalne, w sposób tradycyjny.

3) Schemat uczenia maszynowego
W skrócie – uczenie maszynowe to nic innego, jak znalezienie algorytmu rozwiązującego dany problem, poprzez jak najlepsze odwzorowanie wzorcowych danych wejściowych oraz wyjściowych (tzw. danych uczących), bez konieczności zaprojektowania czy implementacji tego algorytmu.
Możliwości uczenia maszynowego
Uczenie maszynowe wykorzystuje się w rozwiązywaniu szerokiego spektrum problemów, które dzieli się na trzy główne typy w zależności od natury zadania:
- Uczenie nadzorowane (ang. Supervised learning)
- Uczenie nienadzorowane (ang. Unsupervised learning)
- Uczenie przez wzmacnianie (ang. Reinforcement learning)

4) Możliwości uczenia maszynowego
W kontekście tego artykułu skupimy się na najpopularniejszym jak dotąd uczeniu nadzorowanym, które najczęściej stosuje się w problemach klasyfikacji danych (np. co znajduje się na danym obrazie, OCR (rozpoznawanie pisma), wykrywanie fałszerstw czy spamu itp.) oraz – co nas będzie najbardziej interesowało – regresji (szeroko pojęte prognozowanie, jak np. przewidywanie pogody czy wspomnianego wcześniej kursu akcji).
Warto wspomnieć, że z roku na rok zauważalny jest bardzo istotny rozwój uczenia przez wzmacnianie, szczególnie w kontekście rozwiązywania problemów podejmowania decyzji w czasie rzeczywistym (np. auta autonomiczne, czy gry o niewyobrażalnym stopniu skomplikowania, jak szachy czy GO).
Sztuczne sieci neuronowe jako narzędzie uniwersalne
Co ciekawe – większość pracowników biurowych mających styczność z arkuszami kalkulacyjnymi (np. Microsoft Excel), w swojej codziennej pracy często nieświadomie korzysta z dobrodziejstw uczenia maszynowego, rozwiązując problemy regresji – chociażby tworząc linię trendu na zbiorze danych zobrazowanych na wykresie. W ciągu paru sekund (kliknięć myszy) można w sposób analityczny wyznaczyć prostą (regresja liniowa). czy też krzywą wielomianową dowolnego stopnia (regresja wielomianowa, tak, jak na rysunku poniżej).

5) Regresja wielomianowa w Microsoft Excel
Regresja liniowa czy wielomianowa jest przykładowym narzędziem wykorzystywanym w nadzorowanym uczeniu maszynowym. Mając wyznaczony wzór prostej/krzywej możemy z łatwością zrobić prognozę przyszłych wartości. Nie jest to jednak zawsze rozwiązanie optymalne (co zresztą doskonale widać na rysunku 5) i istnieje wiele innych technik, które można wykorzystać w celu rozwiązania danego problemu. Część z nich została zebrana na poniższej grafice:

6) Metody i techniki uczenia maszynowego
Nie da się nie zauważyć, że wszystkie problemy, które adresuje uczenie maszynowe (nie tylko te związane z regresją i klasyfikacją, ale również inne, jak klastrowanie) można z powodzeniem rozwiązać wykorzystując sztuczne sieci neuronowe (ang. Artificial neural networks).

7) Porównanie biologicznego oraz sztucznego neuronu
Sieci neuronowe są matematycznym odwzorowaniem biologicznego układu neuronów znajdujących się w naszych mózgach. Pojedynczy neuron, podobnie jak ten rzeczywisty, zajmuje się przetwarzaniem sygnałów – mówiąc w języku bardziej matematycznym, realizuje funkcję, która transformuje wektor sygnałów wejściowych na sygnał wyjściowy:

Szczegółowy opis działania oraz procesu uczenia neuronu (dobierania odpowiednich wartości wag) jest zdecydowanie materiałem na osobny, bardziej techniczny, artykuł, i nie będę się tutaj zagłębiał w dalsze szczegóły. To, co w tym momencie najistotniejsze, to fakt, że pojedyncze neurony mogą być łączone ze sobą w sieci o różnych topologiach, w zależności od typu problemu, który chcemy rozwiązać, a do najpopularniejszych architektur sieci zaliczamy:
- Wielowarstwowe perceptrony (ang. Multi-layer perceptron), MLP
- Uniwersalna, najprostsza topologia sieci, którą można wykorzystać do rozwiązywania dowolnego problemu
- Sieci konwolucyjne (ang. Convolutional Neural Networks), CNN
- Sieci, które swoje działanie opierają na matematycznej operacji splotu (ang. convolution), najczęściej stosowane w obróbce obrazów 2D oraz 3D
- Sieci rekurencyjne (ang. Recurrent Neural Networks), RNN, w tym LSTM (Long-short-term memory neural network)
- Sieci posiadające specjalne neurony, posiadające własną pamięć, znajdujące zastosowanie w rozpoznawaniu mowy, przetwarzaniu tekstu (NLP) czy analizie szeregów czasowych
- Sieci GAN (ang. Generative Adversarial Networks)
- Sieci umożliwiające generowanie sztucznych danych, które będą nieodróżnialne od oryginałów (np. generowanie ludzkich twarzy, powielanie podobnych zbiorów danych, tworzenie sztucznych scen)
Data Science oraz modelowanie
Skuteczność modeli tworzonych z wykorzystaniem technik uczenia maszynowego w głównej mierze opiera się na jakości i ilości danych, które zostanę użyte w procesie uczenia. Samo zdobycie odpowiednich danych jest jednak dopiero początkiem drogi, najczęściej surowe dane należy poddać żmudnej analizie oraz obróbce, zanim będzie można je wykorzystać w procesie uczenia. Całokształt działań związanych z przygotowaniem danych nazywamy Data Science (inżynierią danych).

8) Data Science
W skład typowych działań poprzedzających proces modelowania wchodzą:
- Czyszczenie danych (Cleanup of data)
- Analiza statystyczna pod kątem korelacji (Initial analysis for correlations)
- Redukcja zbędnych informacji (Features reduction)
- Ekstrakcja dodatkowych informacji (Features extraction)
- Pozbycie się anomalii (Removal of outliers)
- Normalizacja (Normalization)
- Zbilansowanie (Data Balancing)
- Sekwencjonowanie (w przypadku szeregów czasowych)
Mając przygotowane w ten sposób dane, można przystąpić do wyboru techniki uczenia maszynowego (rodzaju modelu, który chcemy stworzyć, np. liniowej regresji albo sieci neuronowej MLP) oraz doboru odpowiednich parametrów uczenia. W zależności od poziomu skomplikowania zadania, ilości danych, architektury modelu, mocy obliczeniowej sprzętu oraz wielu innych czynników, proces samego uczenia może trwać od kilku sekund do wielu godzin/dni. Mając jednak odrobinę szczęścia, po skończonym uczeniu można cieszyć się modelem, który będzie realizował poszukiwaną przez nas funkcjonalność (gotowy algorytm, mimo że nie napiszemy przy tym ani jednej linijki kodu mówiącej maszynie, jak ma ten problem rozwiązać).
Prognoza zarażeń wirusem SARS-CoV-2
Problem przewidywania liczby zakażeń koronawirusem w Polsce oraz na całym świecie jest nietrywialny i można porównać go do analizy kursu akcji na giełdzie. Nie wiemy, czy jutro nie wybuchnie kolejne ognisko choroby, którego nikt się nie spodziewał. Liczba potencjalnych zmiennych jest bardzo duża, a co dodatkowo utrudnia rozwiązanie problemu, to fakt, że fala zakażeń nie jest symultaniczna we wszystkich krajach – w Chinach obserwujemy już wygasanie epidemii, a w Brazylii szczyt zachorowań prawdopodobnie jest dopiero przed nami. Co więcej – niektóre kraje wykazują nietypowe wzorce (np. Tajwan) i ich obecność podnosi poziom skomplikowania zadania. Biorąc to wszystko pod uwagę – brzmi to, jak idealny problem, który można spróbować rozwiązać uczeniem maszynowym. Z technicznego punktu widzenia – mamy tutaj do czynienia z zadaniem regresji szeregu czasowego.
Dostęp do odpowiednich danych (szczęście w nieszczęściu) nie był dużym wyzwaniem – w Internecie znajdują się setki wszelakich zbiorów danych gromadzonych w sposób regularny. Najwięcej uwagi poświęcić należało samej obórce danych, czyli części Data Science (80% całkowitego czasu) oraz przygotowaniu odpowiednio zbioru uczącego.
Kolejnym krokiem było modelowanie, a co za tym idzie, trudna decyzja o wyborze odpowiedniego typu modelu. Biorąc pod uwagę uniwersalność sieci neuronowych, w pierwszej kolejności zastosowałem sieć typu MLP, a następnie spróbowałem wykorzystać sieci konwolucyjne (które wbrew pozorom i powszechnej opinii z powodzeniem można stosować nie tylko w analizie obrazów, ale również jako alternatywę dla MLP, czy sieci rekurencyjnych w modelowaniu szeregów czasowych). Ku mojemu zaskoczeniu, obie architektury (MLP oraz CNN) w zadowalającym stopniu poradziły sobie z odwzorowaniem dotychczasowych krzywych zachorowań dla większości krajów na całym globie, a co więcej – umożliwiły prognozowanie przyszłych wartości związanych z rozszerzaniem się zakażenia, co daje możliwość stwierdzenia, czy dany kraj ma już „najgorsze za sobą”, czy może wszystko dopiero przed nim.

9) Predykcja ilości potwierdzonych zakażeń na COVID-19 w Polsce na 7 dni do przodu na dzień 25 maja 2020
Dokładność działania obu modeli oscylowała w granicach 70-75%, z zaznaczeniem, że proces uczenia sieci konwolucyjnych był zauważalnie szybszy (wynika to bezpośrednio z różnic w topologiach oraz sposobie działania sieci MLP oraz CNN). Wynik ten, zapewne, można by znacząco poprawić, poświęcając więcej czasu na dobór odpowiednich parametrów uczenia, czy też poprzez wykorzystanie innych typów modeli (np. sieci LSTM).
ThingWorx w służbie wizualizacji
Tworząc modele z użyciem technik uczenia maszynowego, bardzo częstym problemem jest integracja z istniejącym oprogramowaniem, czy też nawet zwykła wizualizacja. Z pomocą przychodzi tutaj oprogramowanie ThingWorx, które z powodzeniem można wykorzystać do integracji z dowolnym źródłem danych, a następnie do stworzenia wydajnych aplikacji web’owych udostepniających pożądaną funkcjonalność.
W przypadku predykcji zakażeń na koronawirus w ThingWorx, zaimplementowana została aplikacja integrująca się z modelem napisanym w technologii Python (z bibliotekami Keras/TensorFlow/Flask), dzięki której możemy wybrać dowolny kraj, przeanalizować dane historyczne dotyczące zachorowań, jak również zrobić prognozowanie przyszłych wartości (nawet do 90 dni wprzód). Dodatkowo, ThingWorx „w locie” przetwarza otrzymane przez model surowe dane oraz, stosując metody numeryczne dokonuje wypłaszczenia krzywych (tzw. smoothing), celem precyzyjniejszej analizy krzywej trendu.
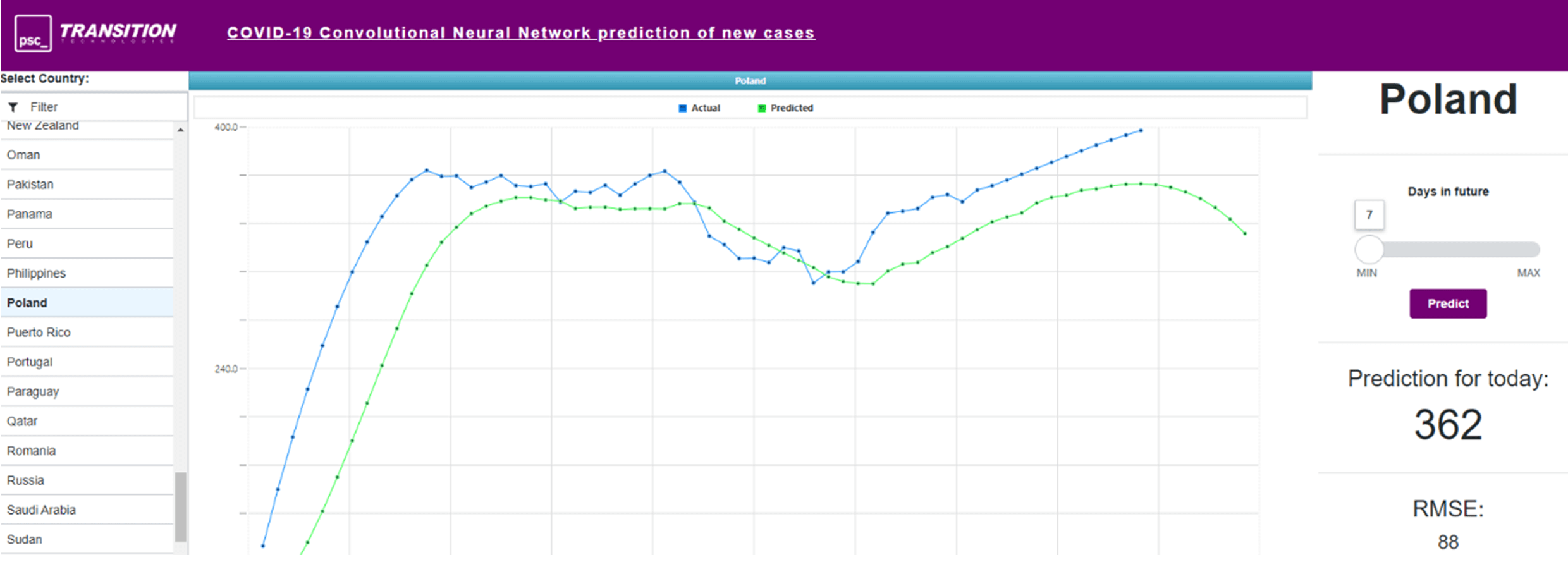
10) Wizualizacja działania modelu w ThingWorx (z dodatkowym wypłaszczeniem krzywych)
Sztuczna inteligencja domeną przyszłości?
Mając na uwadze fakt, że uczenie maszynowe można zastosować wszędzie tam, gdzie zdefiniowanie algorytmu jest nietrywialne, można by pokusić się o stwierdzenie, że programowanie tradycyjne odchodzić będzie do lamusa – no bo, po co się męczyć i głowić nad zaprojektowaniem algorytmu i implementacją programu, kiedy maszyna może się za nas „nauczyć”, jak taki algorytm powinien wyglądać, i zrobić całą „brudną robotę” za nas – i to całkiem skutecznie, jak widać na przykładzie tego artykułu oraz wyników uzyskanych podczas prognozowania potwierdzonych zakażeń wirusem SARS-CoV-2. I pewnie trochę w tym prawdy jest, bo w przeciągu najbliższych paru lat technologie związane z AI oraz uczeniem maszynowym będą zapewne standardem w portfolio usług większości dzisiejszych „tradycyjnych” programistów.
Jeśli szukasz firmy oferującej rozwiazania z zakresu Internet of Things i Data Science zapraszamy do kontaktu!