Data Migrations in PLM: how to secure your company’s most important assets – information


Migrating data to a PLM system is often a very complex undertaking, where business environment and ways in which data is being operated on play a key role. A Migration – what is it, what approaches are the most common and what challenges lay ahead of each one? These and more questions are answered in this article.
What a data migration is and when do you (may) need it
A data migration is the process of moving data from one system (source) to another (target / destination).
Usually PLM data migrations result from:
- Replacing an existing data management system (possibly even a PLM system) with another one.
- Ingestion of data from another system into a business’ main PLM system (for example: after acquiring a company).
- Merging multiple data sets into a single source-of-truth system.
- Demergers and business splits (organizational as well as systems only).
- Cleaning up an organization’s data.
Value of proper migration to business
Imagine Tesla or Apple losing their entire databases containing their product definitions, documentation, change history and more. Yes, they do have some of the brightest engineers worldwide, so they would likely be able to re-build their knowledge base and data sets in most part… eventually… However, regardless of how brilliant they are, such a thing would likely lead to their downfall – or at least to severe problems short- and mid-term, along with more than a few people getting fired.
Now imagine your organization is moving from a legacy PDM system to a new, shiny PLM. Imagine that your closely curated, built over dozens of years and cuddled each night CAD models along with terabytes of meta-data will be moving with you. Imagine what would happen if you lost say… 20% of that data during the switch to PLM because the migration was not performed accurately.
Would you be willing to take that chance?
Organizations these days are often nothing without their data. This is why they are protecting it so tightly from competition, but also from loss. Ensuring company’s data completeness and coherency creates employment for countless database engineers and administrators worldwide.
Migrations result from change, which automatically causes many to be sceptical towards it. However, they are an integral part of that change and often cannot be avoided – that is, unless we want to lose our precious data, right?
So, what can I do to secure my invaluable information?
A proper migration strategy, followed by its careful execution, makes the pain of moving to a new system is significantly less felt throughout the organization. It is key to ensuring that the data set in your target / destination system is complete and your engineers can start utilizing it efficiently from day 1, almost like there was no change at all.
What’s more, a properly executed migration will allow your organization to identify previously undetected issues in your data sets, creating the possibility to fix them while migrating. Believe it or not, but sometimes migrated data sets are actually completer and more coherent than source ones, and better-quality data equals better quality work and products.
What a data migration is not
- Upgrading an application / system without any modification to the database.
- Upgrading the database without any modifications to the data model.
Types of and approaches to data migrations:
Big Bang
A „Big Bang” migration means moving the entire data set and user base from the source system to the target system in one run, resulting in completely switching off or locking the target system and business starting to use the new one. This is by far the most common approach to migrations when the ultimate goal is to completely retire/replace the source system.
The drawback of this approach is a need for locking access to both old and new systems while the actual migration is executed. This “blackout” for users can last as long as a few days, but migrations are often executed during the weekend to mitigate the impact on the business.
A “Big Bang” migration does not mean that it is done without preparation. If properly executed, it should follow the approach described in section 3. Migration Process overview.
Additionally, switching the entire organization to a new system may require putting significant effort into training staff to use new software efficiently as not to paralyze the organization after the migration.
User-centric Big Bang
Whereas a traditional „Big Bang” migration moves all users and all (relevant) data to a new system at the same time, some opt for a more complex strategy where not all data is moved to the new system up until the very last moment until users actually start using it.
Initially a snapshot of the source system is created (or sometimes the source system is cloned in its entirety), relevant data is identified and migrated into the target system, all while users keep working in the source system. Afterwards a delta between the snapshot and the current state of the source system is identified and migrated to the target system along with all users.

This approach allows minimization of the blackout resulting from a traditional “Big Bang” approach but requires careful attention to be put into calculating and importing the delta as to not corrupt business data.
Phased / Incremental
Imagine an organization working in departments, each utilizing a relatively independent data set in the source system. A phased/incremental migration would move each of these departments to the target system independently, one at a time.

This elongates the lifetime of the source system, but it allows to flush out any issues with the target system before the entire user base switches on to it, thus resulting in a much smoother overall experience to the business. It also allows an organization to distribute staff training across a larger time span, making it much less painful.
However, as you may imagine, it’s not all sunshine and rainbows. This approach is quite more complex and requires additional effort on both organizational and technical level because data in the source system may still be alive, even if it was already migrated to the target system. A process needs to be defined and implemented for dealing with these overlaps (and/or discrepancies) between migration chunks, as well as users’ needs for accessing data not yet present in the target system.
This can be done by ensuring each object has a clearly identified “master” (i.e., either source or target system) at any given point in time – and ensuring both the migration team and users are aware of this and refrain from making modifications to in the “non-master”.
While we have been asked many times to perform a phased migration, it was usually impossible to identify fragments of data used by only one department – which is a prerequisite to be able to utilize this approach. Due to these interdependencies, we usually ended up recommending (and performing) either a Big Bang or an incremental migration.
Coexistence
This may be the trickiest approach to a migration. In fact, existing migration tools (for Windchill, and I would assume similarly for other large PLM systems) currently do not support this kind of migration. I will leave the description here for reference and awareness, but please remember that this approach may not be possible in a PLM migration.
A Coexistence migration assumes that both source and target systems must be kept in-sync long enough for the migration to be completed, with potentially any of them being used at any point in time. This requires establishing a bi-directional communication interface between both systems to ensure that data is indeed synchronized.
This approach aims at minimizing impact of the migration, allowing for a much smoother transition to a new PLM system and relatively easier detection and correction of any errors.
On the minus side, as mentioned earlier, this kind of a migration is much trickier to execute: not only because of the need to constantly synchronize both systems, but also performance takes a hit and testing can be difficult. Furthermore, if data in your source system is bad, it will be similarly bad in the new system (which is sometimes referred to as “GIGO” – garbage in, garbage out).
Migration process overview:
To better understand the process of migrating data, we first need to understand the underlying concept. Most migrations are based on a something called “ETL”.
ETL stands for Extract-Transform-Load, which is the most common denomination (methodology) of approaching data migrations, which first became popular in the 1970s. It divides each migration into iterations consisting of the following phases:
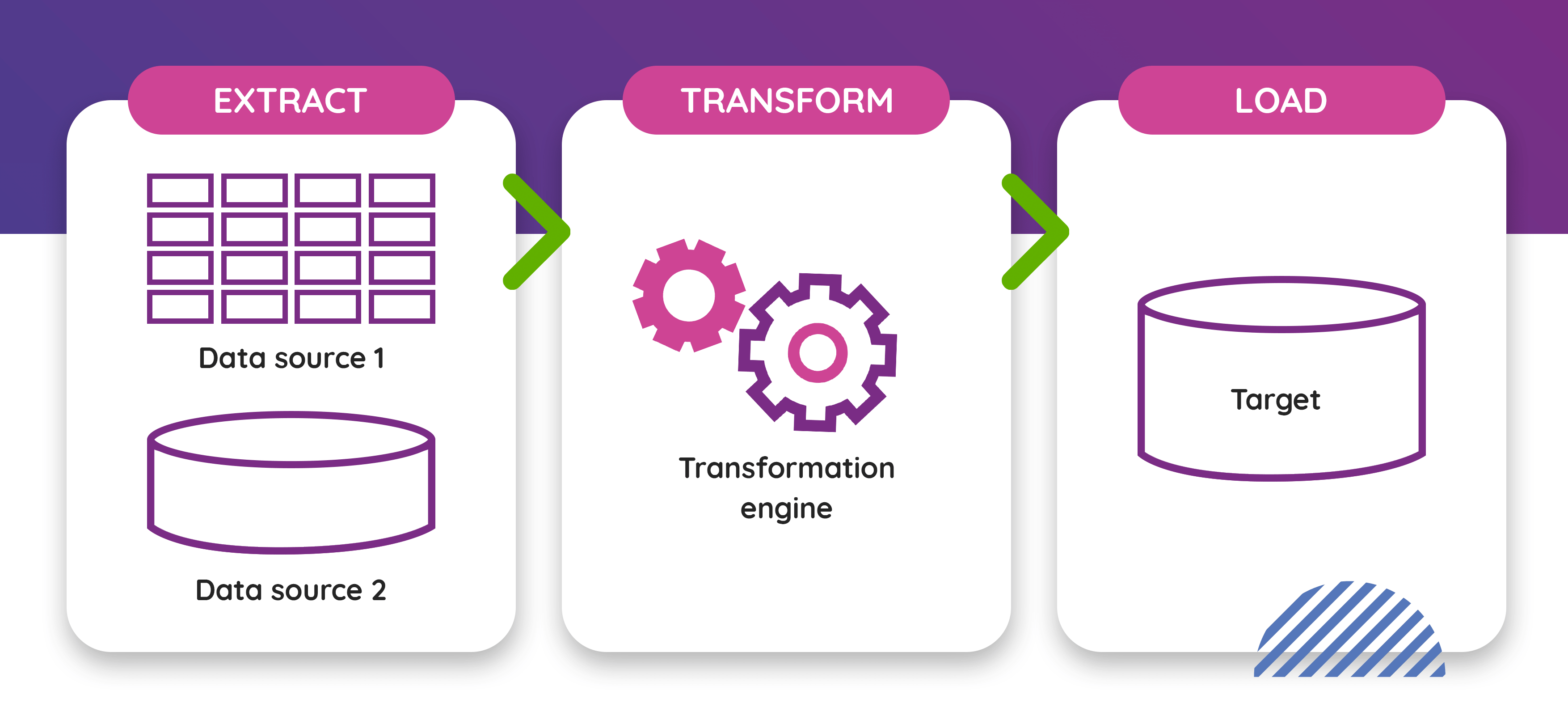
- Extract: get the data out of the source system (-s) into a staging area
- Transform: apply data transformation to align the existing/source data model to the target one. This is where modifications and/or fixes to data are made. It is also common for this phase to filter data which is supposed to end up in the target system. Such filtering can include, for example, removing garbage or old, unneeded items.
- Load: get the transformed data into the target system.
A proper ETL process will ensure resulting data conforms to requirements and standards through identifying and fixing any issues with data quality in the source system (-s).

Example:
Often you may see an abbreviation ETVL, which adds “Validation” into the mix, but most professionals assume validation is a must anyway and simply omit the “V” in the naming.
Elements necessary to succeed:
- Proper definition of source and target data models
Moving from one system to another – unless it is a version upgrade of the same system (but that’s not really a migration) – means you will be moving from one data model to perhaps a completely different one. They may not align nicely out-of-the-box and work must be done mapping each important piece of information (such as object attributes, etc.) from the source to the target. This should be done as an up-front exercise to detect any early (and obvious) discrepancies between data models which might jeopardize the whole migration.
- Cooperation from Subject Matter Experts (SMEs)
Let’s face it: There will always be issues with source data, or how it should translate to the target data model. These kinds of issues can only be addressed properly if an organization’s SMEs can provide guidance on what is important, what is correct, and what isn’t. These SMEs must be available to the migration team without any avoidable overhead and/or delay to ensure that the migration is progressing smoothly.
- Communication
As in all life, communication is key: between business executives and the migration team, organization’s SMEs and the migration team, SMEs and executives, and so on. Properly defined and closely monitored goals, milestones, timelines and results ensure transparency of the entire process and greatly contribute to success of the engagement.
- Experienced team to prepare and execute the migration
You don’t usually want interns or new hires messing around with systems crucial to your enterprise. The same is true for migrations. If you don’t have the necessary expertise to execute a migration in-house, look to a good service provider or system integrator who can supplement your team, guide you during the project – or take the responsibility off your shoulders entirely. Don’t be cheap, though: Your precious data might not like being handled in an unprofessional manner. Remember that you’d not be paying only for workhours during the migration project, but for the years of building up experience and expertise.
Pre-migration steps (planning)
Start off with filling in a basic questionnaire, asking questions like:
- What are the source and target systems (including versions)?
- What are the source and target databases (including version)?
- How many object types do you want to migrate (Parts, CAD files, documents, , etc.)?
- How many objects of each type do you want to migrate?
- Do you only want to migrate the latest versions, or the entire history?
- Do you have any customization to the data model/source system which would need to be recreated in the target environment?
- Will you be able to provide staging environments which will reflect your production one?
… and so on. Please reach out to CONTACT for a full questionnaire if you are interested in migrating to PTC Windchill PLM.
Answers to questions like these will give migration experts an idea as to how complex the process will be, and how much effort will be required to complete it. It will also allow identification of any early risks, such as data type incompatibility between source and target systems.
Once that is done, plan a session (or multiple sessions) between your organization’s SMEs and the migration team. This session should follow an agenda allowing the migration team to understand your current environment and the data residing within it, as well as giving them an idea as to what the result of the migration should look like.
The session (-s) should result in creation of a comprehensive plan for your migration, which should include first estimates of timelines and milestones. Don’t blindly trust any in-advance estimates – this is the earliest point when you can get a relatively accurate cost and effort estimate.
Once the plan is complete and accepted by the business, the migration team can start getting their hands “dirty” and execute the first test migration.
Why test?
Because you can never assume that everything will go perfectly smooth right from the get-go.
Why do we do test migrations?
A typical migration can be a long and complex process, dealing with enormous amounts of data created in the source system over many years. There will be issues with this data. It is impossible, however, to say up-front how many issues there will be. It is possible that the source data set is quite nicely aligned with the target data model. It is also possible that the source data is in a really poor state and will need lots and lots of work to get straight.
This is where test migrations come into play.
It is strongly suggested not to assume that the data set migrated initially is in any way complete or error-free. On the contrary – the first run will likely result in a multitude of errors, resulting in an incomplete data set. Data cleansing and transformation script creation then starts, allowing elimination of errors identified during the first run.
The second test migration utilizes the abovementioned items to address issues with the data, resulting in a more complete data set after the 2nd pass.
However, many errors will remain undetected during the first run, as some may be related and/or cause a chain reaction. Do not be surprised, then, if the 2nd pass results in new, previously undetected issues.
Rinse and repeat, the migration team addresses these new issues and enhances their scripts to ensure even better resulting data quality for a 3rd, 4th, or n-th test migration pass. Each such pass is validated by customer’s key users and each such pass gets us closer to 100% data completeness and integrity in the transformed data set.
It is up to key users and the migration team to define what completeness percentage is acceptable by the business, be that 100% or a lower number. Once this level is reached, one final rehearsal migration should be executed before production migration to confirm proper behaviour of all scripts.
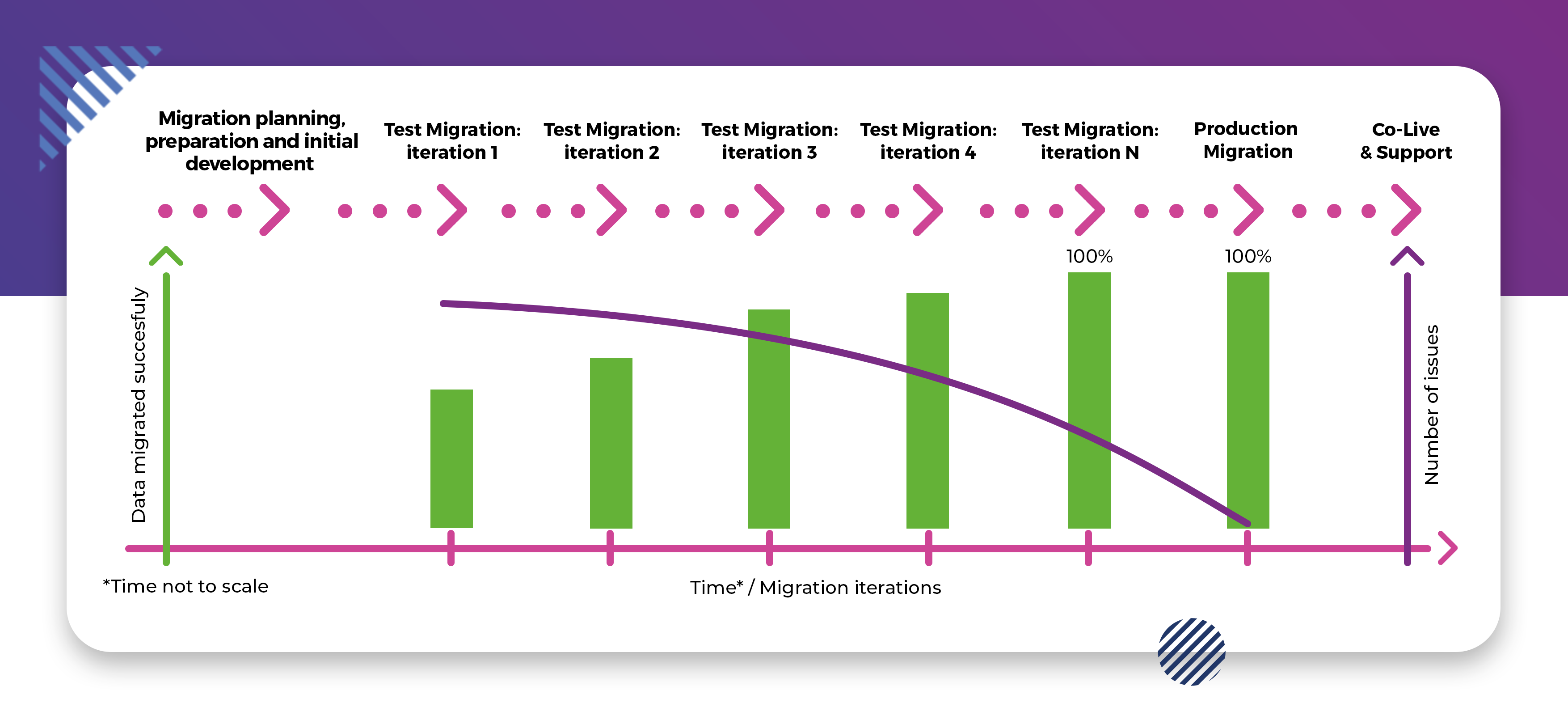
The number of test migrations depends on progress in resolving issues, which is in direct correlation with data complexity and quality.
Please note that it should be of key interest and responsibility of an organization’s key users to validate data after each test run. After all – if someone is going to suffer from loss of data during the migration, it will be them.
Common Problems in PLM Data Migrations
- Data quality (source)
Organizations often don’t know how messy their data is until they have to move it to a different system. This is where collaboration with SMEs and the efficiency of your migration team comes into play. These issues can all (or mostly, at least) be corrected during the “T” of the ETL process.
Obviously, you don’t want to do it manually (good luck with hundreds of thousands of objects…), so automation and scripting play an invaluable role here. The migration team, if guided correctly by SMEs, can ensure your target system has data of quality your organization may have never seen before.
- Constantly evolving data (systems)
Whether you are executing a “Big Bang” migration or a phased one, the data set will constantly be evolving – unless you are willing to stop your operations for a month or so (sic!). New and updated data is always somewhat of a risk to the migration process, as new issues may arise which have not been identified in test migrations.
Proper test migrations do mitigate that risk quite significantly, though, and any issues with data after a migration can always be updated post execution. Just make sure your migration team is there to stay to support you after the migration itself – at least for a while.
- Performance
When migrating to a PLM system you will likely need to move huge amounts of data. That takes time, regardless of whether you are running on-prem or almost-infinitely-scalable-Cloud. However, many elements of a migration process can be automated via scripts, including data cleansing. If written incorrectly, these scripts will severely hurt the performance of the migration process.
Always make sure to benchmark performance of test migrations before running a production one to ensure your requirements towards the timelines (acceptable system downtime before cut-over, etc.) are met. If they are not – think about getting yourself better experts to optimize further. Remember, though, that you cannot optimize and compress forever. Moving large amounts of data sometimes simply does take time and there will not be much you can do about that.
Please note that the above list is not exhaustive. It only mentions the most common (and problematic) issues which we faced through the last 15-or-so years. A thorough analysis of your existing system will help identify any potential risks and bottlenecks, so make sure you pay enough attention to any pre-migration workshops and activities.
Customer’s story of a successful PLM Migration
This is a good time to look at an example of a data migration TTPSC performed for a large automotive customer using PTC’s Windchill PLM system. This particular migration was aimed at moving this customer from a fully-externally managed Cloud instance into a custom AWS-based Cloud environment where they would have full control of all system components while maintaining high levels of automation. At the same time, the version of Windchill would be upgraded from 11.0 M030 (source) to 11.1 M020.
From a migration perspective the biggest challenges included:
- moving many objects of unsupported types, which required creation of custom extractors and loaders, including: Project plans, Promotion Requests, Discussions, etc.
- moving users while modifying groups and roles
- moving existing custom workflows, including the entire history of modifications (especially complicated and requiring much analysis and preparation).
There was one interesting requirement towards this project, namely an unmoveable completion date, correlated with the end of the agreement of the customer with the managed PLM provider. This forced the team to align their plan to a fixed deadline. However, as is displayed by the fact that the project was completed successfully, even complex processes (such as a data migration) can be somewhat adjusted to fit certain circumstances.
In total, over 1 600 000 (one million six hundred thousand) objects were migrated (all successfully). The entire project (including setting up the infrastructure and advanced automation around it – read more about DevOps and automation for PLM systems here) took roughly 5 months to complete. As a result, the customer received a fresh system in the latest stable version with all data migrated, all set up in a custom Cloud infrastructure allowing infrastructure cost optimization, disaster recovery, uptime control and rapid (hours at most) provisioning of new ready-to-use environments for development and other purposes. Needless to say, the customer was extremely happy with the result.
You can find more information about this project in a success story

Summary
Why did I take up all your time to read through the above?
The answer is simple: To build your awareness in what may be the most important aspect in your new (or updated) PLM implementation. While your beautiful, complex and/or automated workflows and triggers may be very valuable, it is actually information (data) that constitutes an organization’s IP and forms the basis for its operations.
By now I hope you understand what kinds of data migrations can be performed, what approaches can be applied, how a migration process looks like, and why it needs the attention and effort which sometimes might at first glance seem not entirely necessary. I know this can be overwhelming, as migrations are a complex and often difficult topic.
In any case, always be sure to leave data migrations in the hands of professionals – internal or external – to ensure your business does not lose the most important thing it has – its data.