Horizontal Scalability in ThingWorx 9


Scalability in web applications has become crucial in the past years. An ever-growing number of devices and clients, connected to the Internet, makes it difficult to handle the traffic by a single server. Scalability is a characteristic of a system that tells if expanding the resources of a server(s) will make it run faster (or handle more load). Not all applications, systems, and networks are scalable by default, they must be designed in a certain way to support scalability. Cloud solutions allow large-scale computing by definition, and IoT platforms should support that as well. When dealing with multiple devices connected to the solution, the platform must stay reliable to manage, store, transform, and analyze huge amounts of data. In the modern world, where everything is connected, an IoT platform becomes a critical point. Every connection causes a reaction – it could be a simple request for current data, but also a more sophisticated query to calculate yearly MTBF (Mean time between failures).
IIoT (Industrial IoT) supports hundreds of thousands of connected devices but also allows to see them as a group as line, shop floor, or an entire factory. Enabling new lines, replacing devices, and expanding the factories should be fast and easy. However, scaling down is also important – switching off the shop floor for energy saving or to reduce supply when demand is reduced is what IoT platform must be able to do. And it must be done seamlessly.

Clustered environments expand by adding new servers. That’s the horizontal scaling – resources of a system are increased along with new nodes. On the other hand, there is a vertical scaling where resources are added to the single node. It is like a dilemma of whether it’s the number or the size that matters.
Vertical Scalability
Scaling vertically (also referred to as up/down) means to add or remove resources within a single server. These resources are CPU cores, RAM, or storage. In this case, the server gets better throughput. However, in a monolithic environment (as opposed to clustered one), when a server goes down, the whole platform might not be accessible, which means it causes downtime. The next aspect is that to add resources the server must be turned off, which means downtime once again. The other drawback is that scaling up has its upper limit. It is not possible to add RAM or CPU indefinitely.

Advantages
- No need to change the application code. The same code will immediately run on the server with new resources
- There is only one server to manage, which makes things a lot simpler and performance boost is easy to see.
- Might be cheaper in terms of manageability and administration
Disadvantages
- Downtimes during hardware changes
- High-end hardware may be expensive
- There is an upper limit, especially when using Cloud pre-defined instances
Horizontal Scalability
Scaling horizontally (also referred to as out/in) means the new nodes are added to the cluster. There is possibly no limit since each new node has its own resources. Making the system more powerful by adding new nodes involves only the cluster manager. This solution is not prone to downtimes. New nodes are added seamlessly, and failing nodes do not put the whole system down. Besides, non-functional server nodes can be easily replaced.
The great thing about horizontal scaling is that it automatically introduces High Availability. This scaling approach can only happen in the clustered infrastructure. Each node has exactly the same settings and application running, making it possible to take over the traffic of another server that went down, either by a user, system, or application error.

Advantages
- Servers are cheaper as nodes are smaller
- Easy to put up fallback plan, as replacing failing nodes is easy
- Scaling is seamless and does not introduce downtime – it is easy to scale out when nodes are not needed.
- Theoretically no limit in scaling
Disadvantages
- Code is more complex which leads to more errors
- Licensing might be more expansive as there are more nodes to license
- Higher complexity in terms of manageability and administration
Active-Active cluster in ThingWorx 9
The scaling opportunity was introduced in ThingWorx 9. High availability and Active-Passive clusters were supported before, but the new version allows to easily scale out/in the ThingWorx platform. In version 9 the ThingWorx cluster can work in Active-Active mode. That means all nodes are taking an active part in the whole solution. This time, every node can handle the traffic – the whole system has more capacity making it possible to connect even more devices. IoT platform needs to be resilient, fit into any use case, handle the peaks of network traffic, optimize the costs and minimize downtimes by avoiding a single point of failure.
With the Active-Passive approach, only one server is live. It performs all processing and maintains the live connections to other systems. In parallel, there is a second passive instance that is updated regularly and shares exactly the same configuration. It is often referred to as a mirror instance. It does not maintain active connections but it will become active once the master server fails.
The new approach gives even higher availability by making all ThingWorx servers active. Data is synchronized between all servers that maintain live connections to other systems and handle the web traffic from clients and devices. Data is being processed in parallel resulting in a cluster that can process more data than a single instance. Moreover, the new Active-Active cluster is scalable horizontally, making it easy to add new nodes to simply increase processing power, or reduce the number of nodes if such processing power is no longer needed. Now, it is possible to manage large amounts of IIoT data at scale.
What is the Active-Active cluster made of?
ThingWorx uses Apache Ignite for data synchronization between nodes. This powerful tool makes the cluster flexible and easy to maintain. Apache Ignite can act as:
- In-memory cache, a powerful, low-latency, high-performance Key-Value cache (also supporting ANSI SQL)
- In-memory Data Grid, an advanced data grid on top of RDBMS allowing to gain 100x acceleration when accessing data
- In-memory Database, a multi-tier scalable out and up across RAM, NVRAM, Flash, and disk
For ThingWorx cluster data must be available for every node immediately. With a load balancer in place, the node which gets the metering data from a device must save that to persistent storage (e.g. InfluxDB) but the same update must be available for other nodes. Thus the Apache Ignite in-memory data caching is the best choice. Data is being synchronized with an underlying database using an additional in-memory layer.
The great thing about Apache Ignite is that it is scalable by default. There is no need to have any additional software, new nodes will be added automatically to the cluster. It is done thanks to Service Discovery – this bit of software makes it possible for every node to discover each other. In ThingWorx 9, Ignite uses Zookeeper Discovery which makes it possible to scale to 100s or 1000s nodes. For smaller clusters, it is advised to use TCP/IP Discovery which is the default for Apache Ignite.
To summarize, the Active-Active ThingWorx 9 cluster consists of:
- Apache Zookeeper to manage and enable service discovery
- Apache Ignite to synchronize data between nodes and speed up database queries
- Multiple ThingWorx platform instances running simultaneously
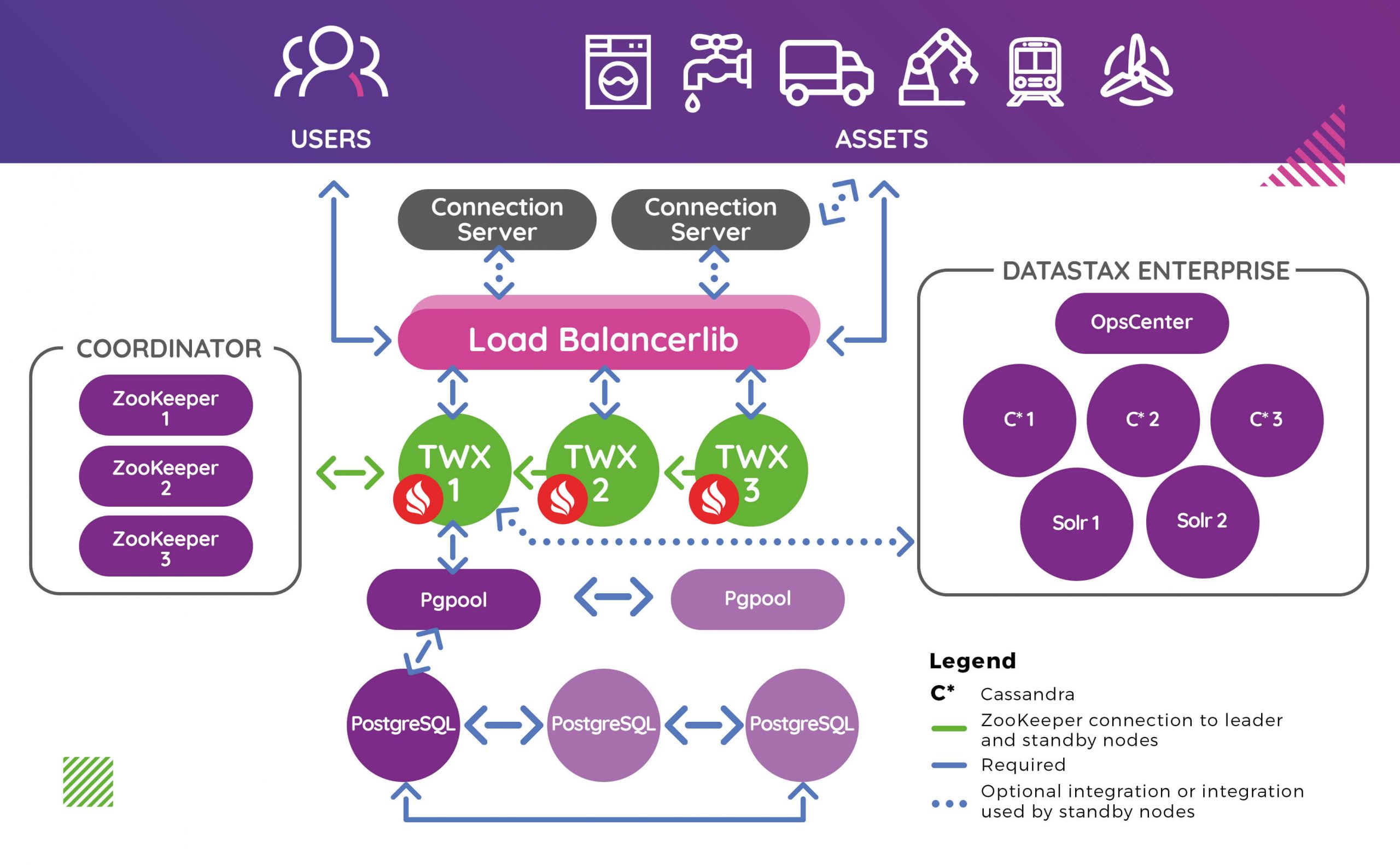
The diagram shows that all ThingWorx instances are live and actively maintain the connections. There is a load balancer that knows exactly how many requests each node has handled and to which node to redirect a new request, depending on the selected balancing algorithm. Everything is managed by Apache Zookeeper, which is also used as a discovery service for Apache Ignite instances. Ignite’s cache is partitioned (by default, but that is configurable) between all nodes. Ignite also allows creating a Compute Grid, which helps with splitting up the tasks between all nodes, making processing faster, and allowing to analyze more data at a time. New opportunities for calculating KPIs and showing them live on the dashboard is just a matter of parallelizing existing algorithms.
Conclusion
Both scaling approaches have pros and cons, and the choice depends on specific use cases. However, most often horizontal scaling is a better option. For the ThingWorx platform, it is a major step forward to support Active-Active clustering. Multiple servers running the same application enable new opportunities in data processing, analysis, and transformation. IIoT solutions that depend on hundreds of thousands of devices can now be implemented with a much better estimation of cost and effort, even higher availability and reliability. It allows saving money while reducing unexpected downtimes.
ThingWorx 9 has become an enterprise platform allowing to easily scale the whole solution out and in. During a holiday season or sports event, the platform will remain reliable even with unexpected peaks in client requests or amount of devices connected. Companies can benefit from horizontal scaling because it helps expand factories with new lines or shop floors, even more, connecting entire factories. High availability will benefit in reducing costs by eliminating unexpected downtimes. That makes it possible to focus on new opportunities instead of planning the fallback scenarios. More processing power allows for more sophisticated machighhine learning models and that opens up new horizons for helping companies to be one step ahead.
If you need help with implementing new or upgrading existing solutions based on ThingWorx, please contact us.