How to take care of the security of serverless applications in AWS?


The AWS re:Invent 2019 conference, similarly to previous editions, was full of interesting lectures, such as breakout sessions, which aimed at familiarizing the participants with a particular technical problem regarding the Amazon Web Services cloud. One of these presentations inspired me to write a few words about the security of applications created in the serverless model. The confidence of the business sector in this architecture is systematically rising, not only among start-ups and small firms but also in large organisations. There are many indications that in the coming years this trend will continue and the number of serverless production implementations will increase. This is why it is a good idea to take a closer look at the tools that AWS makes available to help programmers, administrators and architects minimise the risk of a data leak or losing control over their software.
When deciding to implement an application in a serverless model, one share the responsibility for the security with the cloud service provider. This is described as the so-called Shared Responsibility Model [1]. Amazon Web Services must take care of securing the whole computing and network infrastructure, the correct configuration of operating systems and part of the software (hypervisor, firewall, etc.), installation of updates and security patches, and the encryption of data and network traffic. On the other hand, the client, being an AWS services direct user, is responsible for implementing their program in such a way as to prevent potential attackers from accessing confidential resources or performing undesirable actions. In other words, the client is responsible for errors in the code and business logic of the application, as well as for proper monitoring of important parameters and event logging.
User authentication
Currently, almost every business application has an access control mechanism. One want to make sure that the user is really who they claim to be and that they only have access to the resources they should have. A static password which is usually stored in the database is the authentication method used most often. Of course, storing passwords as plaintext is unacceptable.
A similarly bad solution is hashing them with poor cryptographic hash functions that have long since ceased to be considered safe, such as MD5 or SHA1. If someone takes security seriously, they should concentrate their attention on one of the modern hashing algorithms, e.g. Bcrypt or PBKDF2. They have built-in key stretching and salt adding mechanisms, thanks to which they are very resistant to brute force, dictionary or rainbow tables attacks.
There is also the possibility of authenticating users without the necessity of storing passwords in any database, or sending them between the client and the server, thanks to the use of the SRP (Secure Remote Password) protocol. To put it simply, instead of a password, it requires the storage of a verifier that is a value calculated following the v = gx mod N formula, where g is the so-called group generator, N – a large enough prime number, and x – the value calculated based on the user’s name, password and salt by the use of one-way hash function.
The potential attacker that would want to break the protocol has to calculate x, in other words, has to find a discrete logarithm. This problem is extremely hard to compute, even knowing the N and g values (assuming that the N number meets specified criteria). Therefore, the SRP protocol can be an interesting alternative to the popular storing of password hashes in a database but one that is also demanding when it comes to implementation.
In this case, do you need to hire a programmer with a knowledge of modular arithmetic to enjoy a secure authentication process in your application? In the serverless world, there is no need for that. Amazon has already hired such programmers to do all the dirty work for you. This is why you can (and should) use the Amazon Cognito service, which frees you from the responsibility of storing user access data.
Thanks to the libraries for many popular programming languages, it will also facilitate the implementation of authentication logic with and without the use of SRP protocol. Cognito allows you to create your own user pool and to integrate with external identity providers, such as Google, Facebook, Amazon or any other provider who supports the OpenID Connect or SAML protocol. This facilitates the implementation of one of the good security practices, identity management centralisation, which can reduce the number of possible attack vectors.
From the application point of view, in such a situation there is only one identity storage, even if in reality user data are stored in many places. The use of Amazon Cognito in your serverless system is a step in the right direction if you want to achieve a high level of security.
Access control to REST API
Your serverless application probably uses (or will use) REST API to exchange data between different components.
In the AWS cloud there is a dedicated service for creating and managing API endpoints, called Amazon API Gateway. Although in this case you also share responsibility for security with the provider, remember that you are the one responsible for the correct configuration. One of the key elements is the so-called authorizer, the mechanism built into the API Gateway that is responsible for access control to your API. Let us consider a piece of simple application architecture presented on the diagram below.

The client application sends requests to one or many REST API endpoints exposed via the Amazon API Gateway service which then calls suitable Lambda functions. If the application has an authentication mechanism, you would probably want to allow only logged-in users to send requests to the API and thus to have access to the restricted resources. The case is simple when using the above-mentioned Amazon Cognito service.
However, to better understand the mechanism of restricting access to the API by using the integration with Cognito, let us start with a quick explanation of what the JWT (JSON Web Token) [2] is. It is a standard that describes a secure method of information exchange in the form of the JSON object, which is encoded and signed cryptographically, thus making you (almost) certain that the data is coming from the expected source.
A typical JWT token consists of three parts – the header, the payload and the signature – divided by a dot character. After the user authenticates, the Amazon Cognito service returns three JWT tokens to your application:
- ID token
- Access token
- Refresh token
The first two contain claims regarding the user identity and are valid for an hour after their generation. The refresh token allows generating the ID and Access token again after they expire without requiring additional user authentication. Cognito generates two pairs of RSA cryptographic keys for each user pool. One of the private keys is used to create a digital signature of the token.
Knowing the public key, both your client application and the API Gateway can easily verify, if the user using the given JWT comes from the right pool and if they are not trying to impersonate another user. Each attempt to interfere in the character chain that creates the token invalidates the signature.
Having this knowledge, we slowly move closer to explaining the secret of how the authorizer integrated with the Cognito pool works. Let us look at the modified version of the architecture diagram presented earlier.
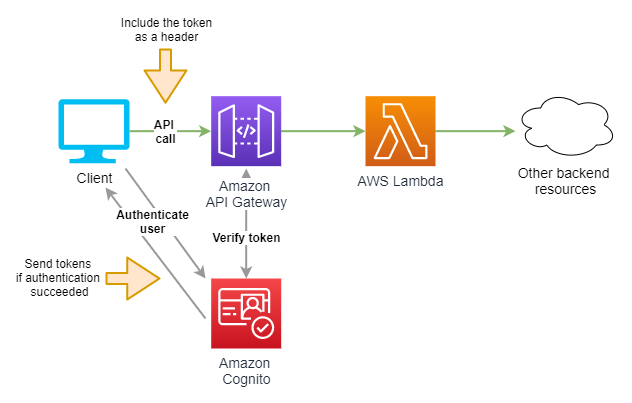
This time the request send by the client application to the REST API contains an additional HTTP header named Authorization. As its value, you set the ID or Access token sent earlier to the application as a response to a successful user authentication. Before transferring the request to the Lambda function, the API Gateway service will make sure that the token was signed with the key tied to the correct Cognito pool and that the token’s validity period had not passed. If the verification fails, the request will be rejected.
Therefore, even if a potential attacker guesses the endpoint’s URL address, they will not be able to successfully send any request to the API while not being a registered user in your application. The solution is simple, elegant and safe, and it is yet another argument in favour of using Amazon Cognito.
Another available type of authorizer is the Lambda authorizer, helpful whenever you cannot use Cognito. As the name suggests, this solution uses the Lambda function that is executed when the request comes to an endpoint. The function contains your own logic of request verification based on the provided token or based on the headers and parameters sent with the request. The Lambda must return an object containing an IAM policy that describes whether the API Gateway should accept or reject the request.
Secure Lambda functions
When writing about security of serverless applications one cannot omit Lambda functions. As already mentioned, the cloud service provider is responsible for the proper configuration of the execution environment and the infrastructure it uses to operate. On the other hand, the programmer must write code free from vulnerabilities and gaps that can be used as an attack vector. One such vulnerability, mentioned in the first place in the OWASP Serverless Top 10 [3] list is the so-called injection, which many can associate with the popular and well described in various sources attack called SQL Injection.
As a reminder: it consists of the unintentional execution of an SQL query (or a fragment of it) placed by an attacker in the input data that your application processes without prior filtering. In the serverless model, this type of data does not have to come directly from the user interface.
Lambda functions are often triggered by a specific event coming from another AWS service, e.g. the creation of a new file in the S3 bucket, modification of a record in a DynamoDB table, or the appearance of a message in the SNS topic. The event object that contains a set of information on such an event and is available in the main Lambda method in some cases can also contain code „injected” by the attacker.
Therefore each byte of input data that enters your function from any source must be appropriately filtered before being used in an SQL query or a shell command. All popular programming languages have functions or libraries that allow the execution of shell commands from the code level. From the technical point of view, there is nothing stopping you from doing the same thing in Lambda functions, but…
To better understand the possible attack vector, let us briefly recall the basics of the Lambda service.

Source: Security Overview of AWS Lambda [1]
To execute your functions, AWS uses special virtual machines, so-called MicroVMs [4]. Each MicroVM instance can be reused for different functions within one account. Also, each instance can contain many execution environments (these are a kind of container) in which a runtime environment chosen by the user works, e.g. Node.js, JVM or Python. Execution environments are not shared between different functions, but – what is important – they can be reused to start another instance of the same Lambda.
Therefore, if you run a shell command that is dynamically created and contains unfiltered input data, the attacker can use this to take control over the execution environment and through this over other function invocations. This will often allow gaining access to confidential information stored, e.g. in the database or files within the /tmp folder, as well as to destroy some of the application resources. This vulnerability has been described as RCE (Remote Code Execution) [5].
Besides filtering and validating input data, one of the most important security practices regarding the AWS Lambda service is the use of the principle of least privilege. To implement it correctly, you must make sure that two assumptions are met:
- Each Lambda in your application should have a separate IAM role assigned. Creating one common role for all functions is unacceptable.
- The role of each Lambda should allow only those operations that are actually being performed. The wildcard (*) symbol should be avoided in policies.
A simple example of the practical use of this rule: if a particular function’s task is to read records from the DynamoDB database, the assigned IAM role must allow only to perform a read-out from a particular table needed in this case. In some situations, you can go one step further and restrict the access only to specific records in the table and specific attributes of those records [6]. Even if the attacker would be able to outsmart you and gain access to the Lambda execution environment, the use of the principle of least privilege would allow you to extensively limit the damage.
Storing access data
As you may already know, when using the Amazon DynamoDB you do not have to worry about the process of connecting and authenticating with a username and password, which is usually the case with database servers. Communication takes place via the HTTP(S) protocol and each sent request contains a cryptographic signature. The programmer usually does not need to know the low-level details of the interface operation because they can use comfortable, high-level API via AWS CLI or AWS SDK packages.
However, in some instances, it is necessary to use a different database, which usually means that access data need to be stored somewhere within your application. Writing them directly into the Lambda function code is not a good idea because then they will probably end up in the Git repository. A much better solution might be the use of Lambda’s encrypted environment variables, and better yet – the use of the AWS Secrets Manager service. It allows for the safe storage of passwords, API access keys and other confidential information. A programmer can easily retrieve such data in the Lambda function code, calling a suitable method from the AWS SDK package.
If your application uses a server or database cluster created via the Amazon RDS service, you can use IAM authentication [7]. After configuring the database and the IAM role attributed to the Lambda function, using a simple method call from the AWS SDK you can download a temporary access token valid for 15 minutes that is used instead of a password in the standard procedure for establishing a connection to the database. The fact that it must be an encrypted SSL connection additionally increases the security level of the solution. However, you should remember about certain limitations – e.g. in case of the MySQL engine, only 200 new connections per second can be established in such a way.
Summary
It is worth remembering that choosing the serverless model does not completely relieve you from having to deal with security issues, however, using the tools and services available in the AWS cloud you can make this task much easier. A detailed description of all the possible dangers found in this architecture and how to prevent them is a topic for at least a large book. This article only touches upon the chosen subjects and is a good starting point for the further broadening of one’s knowledge about this subject. I would advise you to read the supplementary materials and to watch a lecture entitled “Securing enterprise-grade serverless apps” on the basis of which this article was written.
- Amazon Web Services, Inc., Security Overview of AWS Lambda. An In-Depth Look at Lambda Security.
- Auth0, Inc., JSON Web Token Introduction
- The OWASP Foundation, OWASP Serverless Top 10
- Amazon Web Services, Inc., Firecracker
- Yuval Avrahami, Gaining Persistency on Vulnerable Lambdas
- Amazon Web Services, Inc., Using IAM Policy Conditions for Fine-Grained Access Control
- Amazon Web Services, Inc., IAM Database Authentication for MySQL and PostgreSQL